Adobe推出超分辨率,细节丰富视频模型VideoGigaGAN
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
视频超分辨率是计算机视觉领域一个非常有难度的课题,主要是将低分辨率的视频转换为高分辨率。在转换的过程中,会面临着两大难题。
第一个是保持输出视频帧在时间上的连贯性,确保帧到帧之间平滑过渡,不出现闪烁或抖动的情况;第二个则是要在放大的视频帧中重建高频细节,以提供清晰和逼真的纹理效果。
虽然目前很多超分辨率视频模型在保持时间连贯性方面取得了显著进展,但是以牺牲图像清晰度为代价,整体看起来非常模糊缺乏更加生动的细节和纹理。
因此,全球多媒体巨头Adobe和马里兰大学的研究人员推出了VideoGigaGAN,这是一个兼顾帧率连贯性和丰富细节的超分辨率视频模型。
论文地址:https://arxiv.org/abs/2404.12388
VideoGigaGAN是基于Adobe、卡内基梅隆大学和浦项科技大学之前推出的,大规模图像超分辨率模型GigaGAN的基础之上开发而成。GigaGAN经过数十亿张图像的训练,能够在8倍放大的情况下,依然生成逼真细腻的高分辨率图像。
但直接将GigaGAN应用在每个低分辨率视频帧,会导致严重的时间抖动和混叠伪影。为了解决这个问题,研究人员对GigaGAN模型进行了创新。

通过添加时序卷积和自注意力层,将GigaGAN从2D图像模型扩展为3D视频模型,同时引入了光流引导模块,更好地对齐不同帧的特征,提高视频的时间一致性和细节丰富性。
时序卷积和自注意力层
时序卷积是一种用于处理时间序列数据的卷积操作,主要用于提取时间序列数据中的特征。
在视频超分辨率的上下文中,时序卷积模块使模型能够捕捉视频帧之间的时间依赖性,从而提高超分辨率视频的时间一致性。
与传统的空间卷积不同的是,时序卷积考虑了时间维度的关系,并在卷积过程中引入时间上的权重。这样可以使得生成的每一帧都受到相邻帧的影响,从而保持了视频序列的时序一致性。
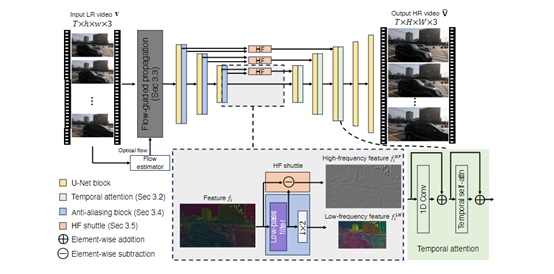
在VideoGigaGAN模型中,时序卷积层被放置在解码器块中,紧随空间自注意力层之后。
这种设计允许模型首先在空间维度上提炼特征,然后在时间维度上进一步加工这些特征。通过这种方式,使模型能够更好地理解视频中的时间动态,例如,运动、变形、切换场景等。
为了更好地捕获视频的细节、纹理以及重建超分辨率,VideoGigaGAN使用了自注意力层与时序卷积一起协同工作。

在解码器块的空间自注意力层中,会计算每个空间位置对当前位置的影响,从而捕捉空间上的细节和纹理信息。然后在时间自注意力层中,计算序列中每个时间步对当前时间步的影响,进一步增强时间的一致性。
光流引导
光流是描述图像中物体运动的向量场,可以捕捉和预测视频帧之间的像素级运动,是计算机视觉中用于估计场景动态信息的重要技术。光流不仅能够提供物体运动的信息,还能够揭示场景的3D结构。
VideoGigaGAN会先使用一个光流估计器来预测,输入低分辨率视频的双向光流图。这些光流图描述了视频帧中每个像素点的运动向量。
然后通过一个双向循环神经网络来处理光流图和原始帧像素,学习时间感知的特征,并能够处理长序列数据,捕捉长期依赖关系。
最后,通过一个反向变形层,将学习到的特征根据预先计算的光流显式地变形。这一流程确保了在超分辨率过程中,即使在物体快速运动的情况下,也能够保持特征的空间一致性。
在光流引导的帮助下,使得VideoGigaGAN模型能够更准确地估计物体的运动轨迹,并在超分辨率过程中保留更多的高频细节,从而生成清晰的超分辨率视频。
本文素材来源VideoGigaGAN论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



