谷歌创新框架:从非结构化数据,实现多模态学习
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
看、听、说的多模态已成为主流大模型的重要功能之一。但在数据爆炸时代,大模型学习文本类的结构化数据相对还好一些,但要去学习视频、音频、图片等非结构化数据非常困难。
目前,从结构化和非结构化数据实现多模态学习,会随着模态数量、输入大小和数据异构性的增加,深度神经网络会变过拟合和泛化效果不佳。
尤其是当在规模有限的数据集上训练时,这一状况就越发明显,例如,经常表现出非平稳行为的时间序列数据。因此,谷歌提出了创新框架LANISTR来解决这些难题。
论文地址:https://arxiv.org/pdf/2305.16556

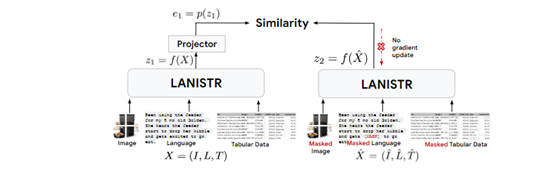
LANISTR是一个基于注意力机制的框架,其核心思想是在单模态和多模态层面上应用基于掩码的训练。
还特别引入了一种新的基于相似度的多模态掩码损失,使其能够从存在缺失模态的大型多模态数据中学习跨模态之间的关系。
多模态融合编码器
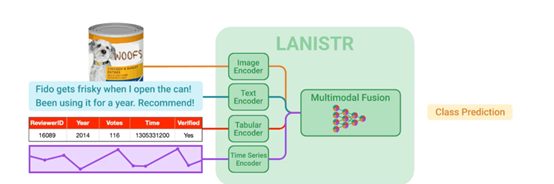
现实数据经常以复合形式存在,单一模态的数据往往不足以捕捉事件的全貌。例如,在医疗诊断中,临床报告和MRI扫描图像才能展现患者状况的全面视图;而在电子商务中,商品描述与销售历史(时间序列)相结合才能更好地预测市场需求。
因此,一个好用的多模态大模型,必须具备将这些分散信息源综合的能力。为了实现这一目标,LANISTR采用了基于Transformer架构的交叉注意力机制。
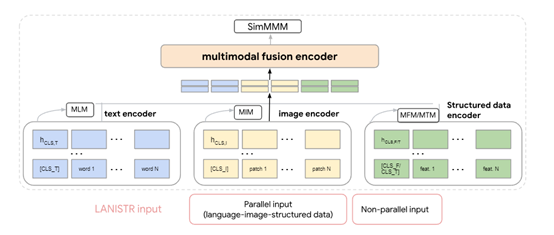
多模态融合编码器可将来自各模态的嵌入向量首先被串联起来,然后通过一系列的Transformer层进行处理。
在这些层中,交叉注意力机制发挥了重要作用,允许模型在不同的模态表示之间自由“询问”和“回答”,使每个模态的特征都能关注其他模态的特征,并根据它们的相关性和重要性进行加权整合。
这一流程与人脑思考有些类似,可根据上下文和情境在不同感官信号间切换注意力,从而实现信息的高效整合。
4种编码器介绍
LANISTR中的多模态融合编码器一共由文本、图像、表格和时间序列4种编码器组成,每种模态都有其独特的表达方式和信息结构。这种机制不仅增强了对单个模态特征的理解,还促进了模态间的交互学习,从而对整个场景有了更加全面的认识。
文本编码器:基于Transformer架构主要处理文本数据。通过掩码语言方法进行预训练,随机掩盖文本中的部分词汇,让模型学习预测这些被掩盖词的能力。这种机制促使模型理解词语间的依赖关系和语境含义,从而提取出丰富的语言特征。
图像编码器:采用Vision Transformer架构用于处理视觉数据。可将图像分割成多个小块,并将这些块视为序列输入到Transformer中,通过自注意力机制学习图像的高层次特征,还会使用掩码图像建模方法,通过重建被掩码的像素或特征来训练,以提取图像的视觉特征。
表格编码器:使用了定制的神经网络结构,针对分类特征的嵌入层来编码每一列数据的特征。考虑到表格数据的稀疏性和多样性,了集成特征选择或降维技术,以聚焦于最有信息量的特征。
时间序列编码器:由于大模型需要捕捉随时间变化的动态模式,时间序列编码器使用了循环神经网络方法,长短时记忆网络和门控循环单元。通过对序列进行建模提取出时间序列的模式和趋势,为后续的多模态融合准备数据。
研究人员在两个数据集上测试了LANISTR的性能,在MIMIC-IV数据集上,当仅使用0.1%的有标签数据进行微调时,模型的AUROC相比最先进的方法提高了6.6%。
在亚马逊产品评论数据集中,仅使用0.01%的有标签数据,模型的准确率提升了14%。值得一提的是,这些改进是在高达35.7%和99.8%的样本存在模态缺失的情况下完成的,这更加证明了LANISTR的多模态学习能力。
本文素材来源LANISTR论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



