Meta等最新研究:多token预测,提升大模型推理效率
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
GPT-4、Gemini系列、Llama-3等开闭源大模型,通常使用的是下一个token预测(Next-token Prediction)的损失函数进行预训练。
这种方法虽然强大,但有很多局限性,例如,需要大量的训练数据才能使模型达到人类儿童的智商,并且随着模型参数的增大推理效率会变差。
因此,Meta、巴黎理工大学和巴黎萨克雷大学提出了一种全新训练方法多token预测(Multi-token Prediction),在训练的过程中要求模型在每个位置上同时预测接下来的n个Token,以提升模型推理效率,并且不会增加预训练时间。
研究人员在130亿、67亿、30亿等多种不同参数的模型对该技术进行了综合评估。结果显示,130亿参数模型在 HumanEval上解决问题能力提高了12%,在 MBPP上解决能力提高了17%,并且推理效率也更好。
论文地址:https://arxiv.org/abs/2404.19737

多token预测架构介绍
为了有效实现多Token预测,研究人员设计了一种巧妙的模型架构。该架构包含一个共享的Transformer主干网络,用于从输入获取上下文表示。
然后该上下文表示被并行输入到n个独立的输出头网络中,每个输出头负责预测一个未来Token。在推理阶段,只需使用单个下一Token预测,输出头即可进行自回归生成。而其他输出头则可被用于加速模型的推理效率。
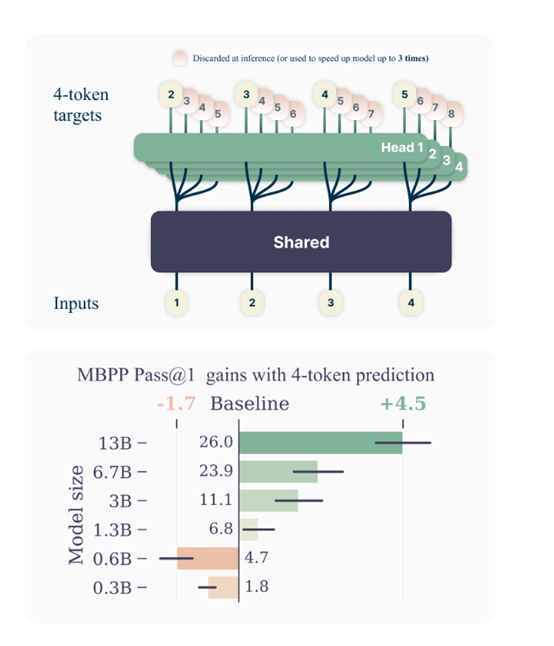
对于训练语料中的每个位置,模型需要使用独立的输出头预测接下来的n个Token。将多Token预测作为辅助训练任务,可以提高模型在代码和自然语言文本方面的任务性能,而不会增加训练时间。
降低GPU内存使用
为了解决多token预测可能导致GPU内存使用量增加的问题,研究人员开发了一种前向和后向传播顺序,模型能够减少在内存中同时存储的梯度数量,从而降低了内存使用量使得训练更加高效。
在前向传播过程中,模型会首先通过共享主干生成潜在表示,然后按顺序计算每个独立输出头的前向传播。对于每个输出头,计算完毕后立即进行后向传播,并释放该头的中间数据,而不是等到所有输出头的前向传播完成后才进行。
在每个输出头的后向传播中,累积梯度到共享主干,而不是在所有输出头计算完毕后才进行。这样可以确保在任何时候,内存中只存在一个输出头的梯度。
优化推理效率
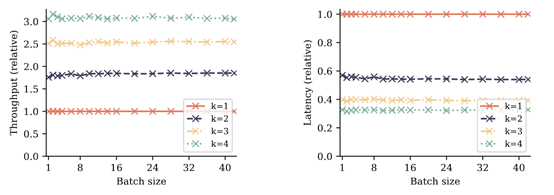
研究人员发现,将多token预测与自推测解码相结合,可以进一步提升大模型的推理效率。与传统逐个token解码不同的是,自推测解码允许模型一次性生成多个token,然后利用额外的输出头并行验证和优化这些预测。
这种方法显著减少了模型生成文本所需的步骤,从而加快了模型的整体推理效率并减少了对算力的消耗。
研究人员在不同参数的模型实验了该优化效果,结果显示,比传统的优化推理效率提升了3倍左右。
本文素材来源Multi-token Prediction论文,如有侵权请联系删除
END




本篇文章来源于微信公众号: AIGC开放社区



