支持中文、开放权重,Cohere最新开源大模型Aya 23
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
5月24日,知名开源大模型厂商Cohere开源了新一代大模型——Aya 23。
据悉,Aya 23共有80亿和350亿两种参数,支持阿拉伯语、中文(简体和繁体)、捷克语、荷兰语、英语、法语、德语、希腊语、希伯来语等23种语言,可生成文本、代码、总结内容等。
目前,Cohere已经全面开放了Aya 23的权重,在遵守CC-BY-NC、C4AI的策略下可以商业化。
35B开源地址:https://huggingface.co/CohereForAI/aya-23-35B
8B 开源地址:https://huggingface.co/CohereForAI/aya-23-8B

在预训练方面,Aya 23基于Cohere Command系列模型,使用包括23种语言文本的数据混合进行预训练。
Aya-23-35B是Cohere Command R的进一步微调版本。预训练模型采用了标准的仅解码器Transformer架构,并行注意力和FFN层、SwiGLU激活、无偏置、RoPE(旋转位置嵌入)、BPE分词器以及分组查询注意力(GQA)。
实验数据显示,在鉴别性任务上,Aya 23模型在所有未见过的任务上都表现出色,这些任务包括XWinograd、XCOPA和XStoryCloze,使用零样本评估。
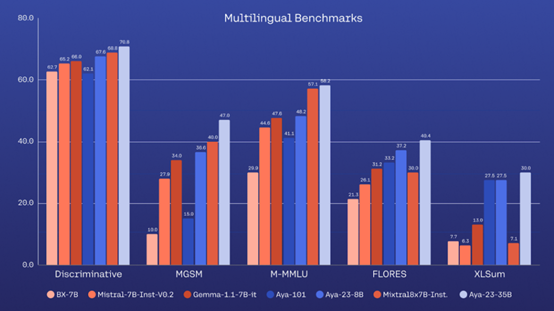
在多语言MMLU评估中,Aya 23模型在14种语言上的表现也优于其他模型。在多语言数学推理方面,Aya 23模型在MGSM基准测试中的表现超越了所有同类基线模型。
在生成任务方面,Aya 23模型在机器翻译和摘要生成上的表现也显著高于其他具有相似参数的模型。
本文素材来源Cohere官网,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



