谷歌发布Veo:文生超1分钟、1080P视频,媲美Sora
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
5月15日,谷歌召开“ I/O 2024”大会,并宣布了100多种产品和大模型。其中,有两款产品令人印象深刻,一个是支持跨文本、视频、音频的多模态AI Agent—Project Astra;另外一个便是视频模型Veo。
据悉,Veo支持文本生成超过1分钟的1080P超高清视频,在文本语义还原、视频动作一致性方面、运镜、帧与帧之间的连贯性、场景切换、光影效果等,可媲美OpenAI的Sora。
不过,Sora发布至今已经3个月了一直处于内测阶段,公测遥遥无期。而谷歌已经将Veo模型整合在文生视频产品Video-Fx中支持申请试用,并且会向开发者开放API。
文章末尾,「AIGC开放社区」还整理了本次I/O大会的所有重要内容,方便大家了解谷歌最新的技术趋势。
申请地址:https://aitestkitchen.withgoogle.com/zh/tools/video-fx
Veo生成视频欣赏
由于平台压缩的原因,视频看起来可能有点糊,实际效果是高清的。通过文本描述Veo生成的一个1分23秒的超长视频,提示词:一个快速穿梭于繁华的反乌托邦城市中,明亮的霓虹灯、飞行汽车、薄雾、夜晚、镜头眩光和体积光线的镜头。
通过未来主义的城市肆虐快速追踪镜头,明亮的霓虹灯标,天空中的星舰,夜晚。一辆汽车的霓虹全息图以光速行驶,电影般的惊人细节,体积光。汽车离开隧道,回到真实世界的中国香港城市。
在烧烤架上,鸡肉和青椒串烤的特写镜头,火焰在旁燃烧。焦距浅,轻烟袅袅,色彩鲜艳。
许多斑点水母在水下蠕动。它们的身体透明,在深海中发光。
一名孤独的牛仔骑着马穿越美丽日落的开阔平原,柔和的光线,温暖的色彩。
一艘宇宙飞船在宇宙的浩瀚中飞驰,星星在其旁划过,高速飞行,科幻感十足。
一只金毛寻回犬在蜿蜒的山间小径上行走,它兴奋地摇着尾巴,探索着荒野的景色和气味。
此外,谷歌还把Veo的生成视频的界面通过Video-Fx展示了出来。使用方法没啥特别的,就是在文本框输入提示词,然后点击生成即可。
一次会生成4个视频,这对服务器的算力有着非常高的要求,不得不说谷歌为了拼视频模型也是下了血本啦。
这也是Sora迟迟没有全面公测的主要原因之一,还没有准备好强大的算力矩阵为用户提供服务。
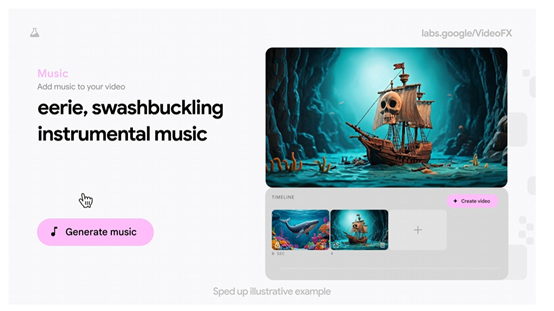
值得一提的是,Veo有一个“Storyboard”模式,支持用户为生成的视频一键添加背景音乐。
Veo模型架构简单介绍
根据谷歌的介绍,Veo更像是一个模型大合集,融合了GQN、DVD-GAN、Imagen-Video、Phenaki、WALT、VideoPoet、Lumiere、Transformer和Gemini等,谷歌很多知名的技术概念和现有的大模型。
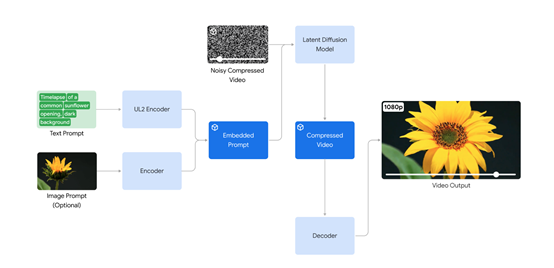
例如,Phenaki是谷歌很早之前便推出的文生视频模型,采用了一个双向掩码转换器架构。在视频帧之间的切换、一致性、关联性方面非常优秀。
WALT则是深度学习领域的一种视频微调技术,可关注模型内部的激活层,通过权重调整来改进模型性能。
Gemini是谷歌最新发布的性能强、消耗低的大模型,有很多种类型可以与OpenAI的GPT系列媲美。
所以,从这个技术合集就不难看出,谷歌是对Veo下了心血的誓要与OpenAI的Sora一较高下。
谷歌2024年I/O大会,重要事件回顾
其实今年谷歌在I/O大会上发布的内容非常非常多,尤其是生成式AI领域成为重头戏。
但由于发布的产品实在太多、太杂,这里「AIGC开放社区」就为大家整理了所有重要事件的简报,方便理解最新技术趋势。

发布了Gemini 1.5 Flash:一个更轻量的大模型,可高效地提供规模化服务。这也是在API 中提供的最快的 Gemini系列模型。
增强Gemini1.5 Pro性能:用户版提供100万tokens上下文窗口,开发者版提供200万tokens上下文窗口。
发布最强TPU-Trillium:这是谷歌发布的第六代AI处理器,与TPU v5e相比,Trillium TPU每个芯片的峰值计算性能提高了4.7倍,但能源消耗却降低了67%。
发布最新文生图模型Imagen 3:生成的图像质量更好、文本语义理解更优秀,目前已经整合在ImageFX中,支持申请试用。
发布音乐模型Music AI Sandbox:通过AI生成超逼真的歌曲,包括流行、摇滚、抒情等。
Gemini的高级订阅用户很快就可以创建定制版本Gem,只需描述你想要 Gem 执行的操作以及希望它如何响应,Gemini 将根据这些说明创建出符合特定需求的 Gem。
谷歌宣布将Gemini系列模型融合到谷歌搜索中,提供规划、推理等多模态功能。
Gemini 1.5 Pro现在可以通过 Workspace Labs 在 Gmail、Docs、Drive、Slides 和 Sheets的侧边栏中使用,下个月会为 Workspace 客户和 Google One AI 高级订阅用户提供服务。
Google Photos中新增“询问照片”功能,使用户能查找特定记忆或回忆图库中包含的信息变得更加方便。该功能由Gemini模型提供服务,并将在未来几个月内推出。
今年晚些时候,Gemini Nano模型会成为Android内置的基础模型,除了文本生成,还支持语音、视频等多模态推理。
谷歌发布了PaliGemma,这是第一个面向视觉-语言的开源模型,针对视觉问答和图像字幕进行了优化。
谷歌预览了Gemma 2,采用了全新架构有270亿参数,性能更强可在单个 TPU 主机上运行。

Gemini模型现已在 Android Studio、IDX、Firebase、Colab、VSCode、Cloud和Intellj中可用,可帮助开发人员提高生产力。
从Chrome126开始,Gemini Nano 模型将内置到Chrome桌面客户端中。
推出LearnLM,这是基于Gemini模型并经过精细微调的用于学习的新模型。LearnLM 已经为谷歌的搜索、YouTube 和 Google Classroom等提供技术支持。
谷歌的SynthID文本水印技术,将在未来几个月内开源。
从上面重要事件不难看出,Gemini系列大模型已经成为谷歌产品矩阵中重要的基础技术之一,这充分说明生成式AI时代已经降临。
只有会用AI的人,才不会被这个时代淘汰,一起加油啦。
本文素材来源谷歌官网,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



