谷歌提出大规模ICL方法——强化和无监督
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
大语言模型在自然语言处理任务中取得了显著的突破,尤其是是在少样本学习和上下文学习(in-context learning,简称“ICL”)方面。虽然在少样本学习中表现出色,但无法探索更大规模的上下文学习潜力。
随着大模型上下文窗口的大幅度增长,例如,谷歌的Gemini 1.5 Pro模型支持100万tokens上下文,使得研究人员有机会探索更多的ICL示例,以增强大模型的学习和输出能力。
谷歌Deepmind的研究人员提出了强化和无监督两种ICL学习方法,可显著提升模型的数学问题解决、文本问答、摘要生成、算法推理、低资源机器翻译等场景能力,同时大幅度降低人工标注的成本。
论文地址:https://arxiv.org/abs/2404.11018

强化ICL
传统的ICL主要依赖于人类生成的示例来学习新的输出模式,但这种方法受限于高质量数据的可用性。而谷歌提出的强化ICL通过使用模型生成的推理链来代替人类编写的示例输出,可有效减少对人类生成数据的依赖。
强化ICL主要通过已有的模型来生成问题解决的候选推理链,从少量或零示例的链式思考提示开始,使模型能够为每个训练问题生成多个推理链。
然后,使用一个独立的评估模块,对生成的推理链、输出对进行打分过滤,只保留高质量的部分,并将它们作为上下文示例应用在模型的学习中。
研究人员在一系列推理和问答数据集上测试了强化ICL性能,结果显示,可以在不依赖额外人工标注的情况下,持续提升模型的多ICL性能。
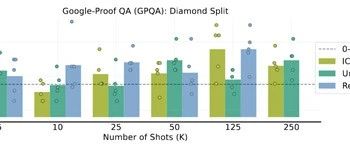
例如,在谷歌的GPQA数据集上,使用强化ICL产生的8192个示例,使得大模型的准确率高达67.8%,大幅超过了仅使用128个人工标注示例50.2%。
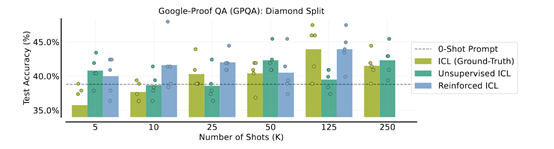
在谷歌的GSM8K编程问题数据集上,使用500个强化ICL生成的示例,模型的准确率达到84%,而仅使用4个人工标注示例时的准确率只有78.1%。
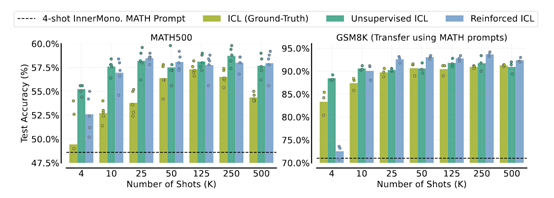
除了大模型的性能获得显著提升,强化ICL还显著降低了人工成本。以MATH数学题为例,生成4000个高质量的问题解答示例,纯人工标注需180人小时,而使用强化ICL生成只需10人小时,大幅度降低了18倍的人力成本。
无监督ICL
无监督ICL不依赖于传统的输入-输出示例对,而是仅通过问题本身的上下文来引导模型学习,帮助模型能够利用其在预训练阶段获得的知识,来理解和解决问题,而无需额外的示例指导。
首先,根据任务的需求,从未标注的数据中选取合适的文本片段作为上下文。这些上下文可以是单个句子、段落或者更长的文本。然后将构建好的上下文输入到大语言模型中,让模型根据上下文的内容进行推理和预测。

最后,将模型推理的结果与真实情况进行对比,计算损失函数并更新模型的参数。但需要注意的是,由于无监督ICL没有标注任何数据,很多示例是基于某种启发式方法或者先验知识实现的。
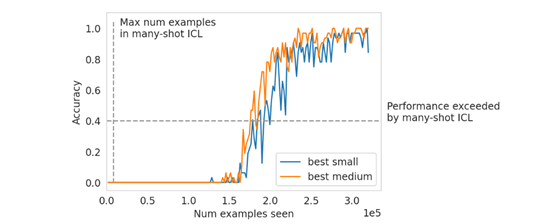
此外,在研究过程中,研究人员还发现了一些有趣的现象,大规模ICL与少样本学习存在差异。但大模型可以克服预训练偏差,并解决具有数值输入的高维预测任务,例如,顺序奇偶预测和线性分类等。
本文素材来源谷歌Deepmind论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



