英伟达开源大模型对齐框架—NeMo-Aligner
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
随着ChatGPT、Midjourney等大模型产品的影响力、应用场景越来越多,为了确保输出的内容安全、可靠,对齐成为开发人员的关注重点和难点。
但现在的模型参数少则几百亿多则上千亿,想通过传统的监督式微调方法来完成对齐效果往往不理想。
因此,英伟达的研究人员开源了安全对齐框架NeMo-Aligner。这是一个包括人类反馈进行强化学习(RLHF)、直接偏好优化(DPO)、SteerLM和自我对弈微调等技术合集,可帮助开发人员极大提升模型的安全性能和稳定输出。
开源地址:https://github.com/nvidia/nemo-aligner
论文地址:https://arxiv.org/abs/2405.01481v1

下面为大家介绍两个效果比较好、常用的NeMo-Aligner对齐方法。
RLHF
RLHF是NeMo-Aligner框架的核心模块之一,主要通过人类反馈来引导大模型学习,使其输出更符合人类的价值观和偏好,同时采用了近端策略算法(PPO)来优化语言模型的行为。
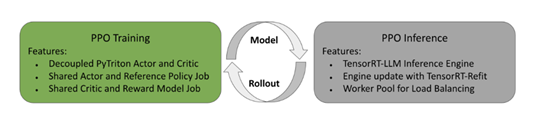
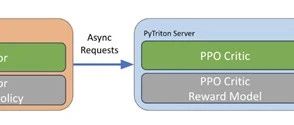
训练过程主要分为三个阶段:初始阶段,从预训练的基础模型开始,进行监督微调。在监督微调中,使用输入提示和期望的回复对基础模型的参数进行更新,使其尽可能地模仿期望的回复。这一阶段是为了确保基础模型能够生成符合用户指令的回复。
奖励模型训练阶段,使用一组设定好的人类偏好数据,例如,问答的特定输出格式,来训练一个奖励模型,以最大化预测奖励与人类偏好一致的可能性。通常,会在监督微调的模型之上初始化一个线性奖励模型头部,并在其上进行训练。
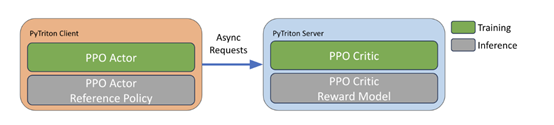
策略优化训练,基于训练好的奖励模型,通过PPO进行优化训练。在训练过程中,使用基于KL散度的正则化项,防止策略偏离起始点太远并利用奖励模型的盲点。
SteerLM
SteerLM主要通过引导大模型的生成流程来实现安全对齐,使用了一种“引导信号”的指导策略。可将开发者希望的输出模式注入到模型的训练中,以引导模型生成更符合预期的响应。
首先,需要准备一个包含输入提示和期望输出的数据集对。这些输入提示可以是用户提供的指令或问题,而期望输出是模型生成的响应。
根据输入提示和期望输出,生成引导信号。引导信号可以采用不同的方式生成,例如,使用规则、基于规则的策略或者其他的启发式方法,可以控制生成文本的风格、主题、情感等内容。
例如,在多轮AI对话中,可以指导模型生成符合用户期望的回答;在文本摘要任务中,可以指导模型生成更加准确和有信息量的摘要内容;在机器翻译任务中,可以使模型生成更加准确和流畅的翻译结果。
本文素材来源NeMo-Aligner论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



