美国修订法案,拟禁止开源类ChatGPT模型出口
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
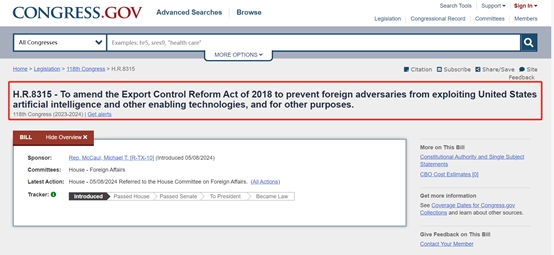
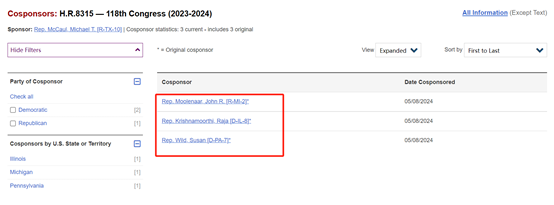
美国国会官方最新消息显示,由民主党成员Wild Susan、Krishnamoorthi、Raja,共和党成员Moolenaar John共同发起了H.R. 8315提案。
修订2018年《出口管制改革法案》,以防止外国竞争对手通过美国AI和其他技术用于其他目的。
这些技术包括类ChatGPT、Midjourney等可生成文本、图片等开源AI大模型,防止用于发动网络攻击、制造大规模杀伤性生物武器等。
目前,该提案处于委员会辩论阶段,如果通过会进入参议院,再通过之后将由总统签署正式执行该法案。
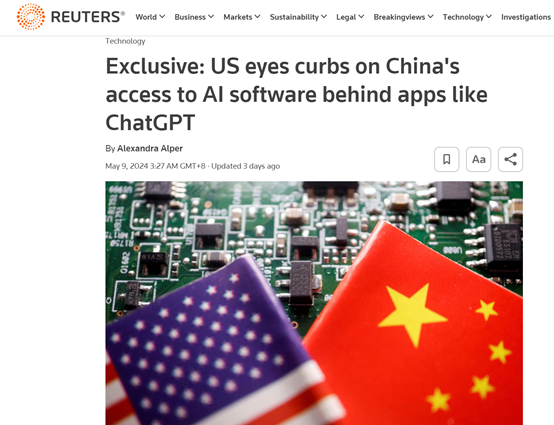
路透社对于该法案进行了独家报道,指出该法案专门针对中国、俄罗斯的,就像限制半导体芯片那样设置监管护栏以防止被赶超。
美国采取的限制方法可能和去年10月的AI行政命令差不多,就是大模型性能阈值达到标准后,开发者必须向商务部报告其AI模型的应用和部署计划。
例如,谷歌Gemini的Ultra是该系列模型中最强大的一款,可能就会被禁止出口使用。
目前,美国商务部拒绝对该法案进行置评,俄罗斯驻华盛顿大使馆也没有立即回应置评请求。
中国开源大模型正在崛起、赶超
说实话,想禁止中国发展AI大模型很难。除非他们把中文训练数据集禁止了,好像又做不到。
如果是2023年2月左右执行了该法令,可能还有点效果。那时候都是摸着石头过河,可用的资料也不是很多。Meta的Llama确实成为整个类ChatGPT开源领域的一盏指路明灯,帮助不少开发者少走了很多弯路。
不过,开源大模型只是一个成品,对于很多没有资金、研发能力的国家来说这招确实很管用。但咱们有着庞大的AI人才库,以OpenAI的团队为例华人就有10多位,并且研发大模型的图纸都在Arxiv、Google Scholar、IEEE Xplore上呢,要是禁这个可能比成品更靠谱一些。
例如,国内的潞晨科技开源得类Sora项目Open-Sora,就是凭借Sora的技术报告和其他AI论文复现出来的,在github已经超过16000颗星,受到了国内外开发者的好评。
现在开源大模型领域也非常的卷都是一开到底,权重、代码、训练数据/流程/细节基本全部开放,并且有一个非常重要的决定因素就是中文数据。
除了ChatGPT、Claude 3等极个别闭源大模型对中文支持很好之外,就连Meta的Llama-3、谷歌的Gemini系列对中文支持并不是很好。如果没有海量中文数据进行蒸馏微调,就算拿到开源模型用处也不大。
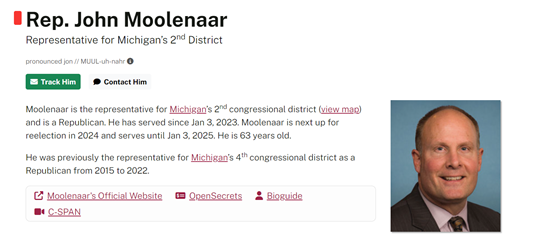
此外,随着开源大模型不断进化,美国的Meta也不再是一家独大,国内的阿里云、清华、北大、商汤、百川智能、零一万物,法国的Mistral AI,阿联酋的TII国家实验室都是开源领域非常强的玩家。
他们开源的大模型产品可媲美GPT-4,甚至在个别测试单元超过了GPT-4。尤其是经过中文指令微调的大模型,相比GPT-4、Claude 3 、Gemini Ultra更适合国内用户。
所以,无论最后这个法案是否会通过,相信对中国AI大模型的发展影响不会太大。
本文素材来源美国国会官网、路透社,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



