英伟达推出LATTE3D:仅需400毫秒,文本生成高质量3D模型
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
英伟达的研究人员推出了文生高质量3D模型——LATTE3D。
与其他的文生3D模型相比,LATTE3D摊销了神经场和纹理表面生成,可以在单次前向传递中生成多视角、高质量的纹理网格。
同时利用3D数据进行优化,通过3D感知扩散先验、形状正则化和模型初始化等方法,实现对多样化和复杂训练提示的稳定性。
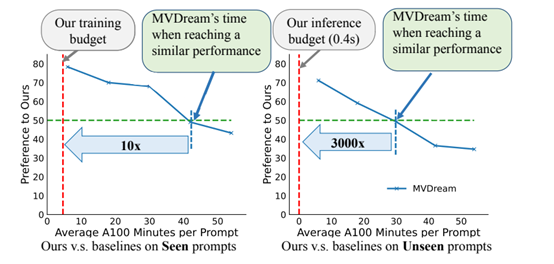
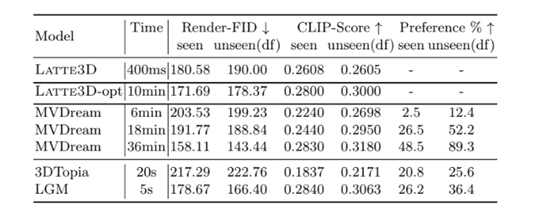
尤其是在生成时间方面,其他模型生成一次可能在十几分钟甚至一小时,而LATTE3D只需要400毫秒就能生成高质量3D模型。
论文地址:https://drive.google.com/file/d/1HZ7EY1jFguiwxxetgQkpljrj0cxbhZXZ/view

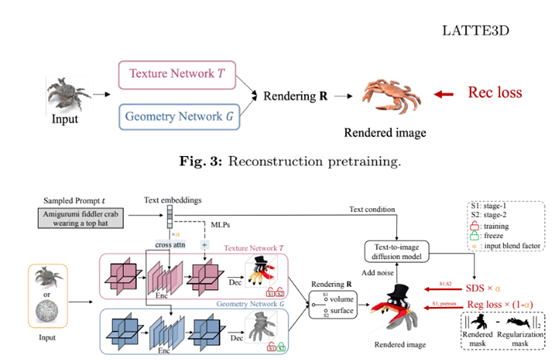
LATTE3D的核心架构由几何网络和纹理网络两大块构成,并且在编码器部分共享参数权重。
几何网络的作用是只生成3D对象粗糙的整体形状和结构,不用追求细节特征。其输入是一个虚拟的球形点云(在推理时使用),通过点云编码器将其转化为三平面特征,再经过U-Net结构的编码器和解码器后,输出为一个体密度场。
纹理网络的任务是为几何网络生成的粗糙3D形状添加高质量细节纹理。其输入也是球形点云,但会被编码为高分辨率三平面特征,再通过一个解码器输出顶点颜色,即为3D网格的每个顶点生成RGB纹理值。
这种简单、高效的双分工框架,使得LATTE3D在生成3D模型时兼顾物体的形态和质量。
第一阶段,生成3D体数据
在第一阶段,LATTE3D的目标是使几何网络能够生成与文本提示相符的粗糙3D体数据。为了高效学习该映射,研究人员设计了一个创新的复合训练目标。
研究人员使用了MVDream训练的3D扩散模型。LATTE3D将几何网络生成的3D体数据渲染为多视角图像,并将渲染结果与MVDream输出的相应图像比较,为模型提供了强化3D一致性监督。
但仅依赖扩散模型的强化监督可能会导致形状失真等问题。因此,研究人员为每个训练提示提取了相关的3D参考形状,将参考形状渲染为2D掩码图像。然后将生成形状的渲染掩码与参考掩码进行比较,形状差异越大损失越高,这种3D正则化可以约束生成形状的整体准确性。

最后,研究人员对上述两个损失取加权平均作为最终目标损失函数,并在训练过程中线性增加3D正则化损失的权重,以确保后期生成形状的准确性。
第二阶段,纹理优化
经过第一阶段训练后,我们获得了一个能够生成粗糙体数据的几何网络。第二阶段则是在此基础上,进一步训练纹理网络,以生成高质量的纹理细节。
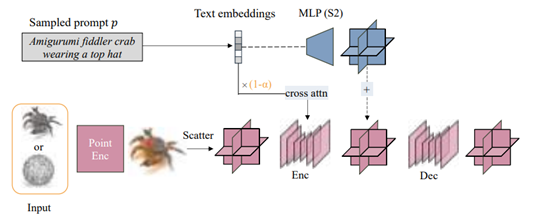
LATTE3D冻结了几何网络的权重,只优化其解码器,并利用神经场的输出来初始化有符号距离场和纹理场,再通过可微分栅格化技术对表面表示进行大幅度优化。
这种基于表面的表示可以更好地捕捉高频几何和纹理细节,从而提高生成结果的质量。
此外,LATTE3D还通过使用3D感知的损失函数和额外的正则化项来训练表面细化模块,以改善生成结果的准确性和细节。
训练数据
LATTE3D使用了一个超过10万个文本提示和3.4万个3D形状的大规模数据集进行训练。这个数据集的规模超过了之前多数的文本到3D生成模型,这使得LATTE3D的泛化能力得到了极大增强。
本文素材来源LATTE3D论文,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



