谷歌开源专业代码模型:对硬件要求低,性能超强!
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
谷歌发布了面向企业、开发人员的全新代码模型Code Gemma,一共有基础预训练、指令微调和快速推理三个版本。
Code Gemma是基于谷歌在今年2月发布的Gemma模型之上开发而成。其参数很小只有20亿和70亿两种,但使用了超过5000亿tokens的代码、数学、文本等数据进行了大规模预训练,能快速生成Python、JavaScript、Java、C/C++、C#等主流编程语言代码。
在代码编程、多语言编程等基准测试中,Code Gemma 70亿参数的性能超过了DeepSeek Coder、 StarCoder2等同类代码模型,并且推理效率和准确率更高。
开源地址:https://huggingface.co/collections/google/codegemma-release-66152ac7b683e2667abdee11
技术报告地址:https://goo.gle/codegemma

Code Gemma简单介绍
为了提升模型的性能,Code Gemma开发团队采用了基于“填充中间”任务的训练方法,对性能进行了大幅度改进,包括使用特定的格式化控制令牌,例如,FIM前缀、中间和后缀,以及文件分隔符等。
还特别针对多文件环境下的代码生成任务进行了优化。通过将代码库中最相关的源文件放在一起,并尽可能将它们分组到同一个训练样本中,可以使模型能够更好地理解和生成基于仓库级别上下文的代码。
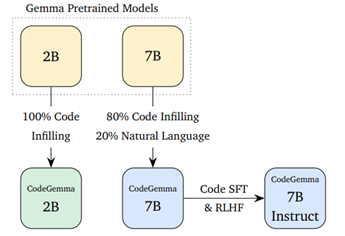
本次发布的Code Gemma系列模型一共有三个版本:Code Gemma 2B 是专门针对代码填充进行训练,其推理效率非常高但对硬件要求却很低,非常适用于对延迟、隐私要求较高的业务环境中。
Code Gemma 7B 是基础预训练模型,主要包括代码填充数据(80%)和自然语言,可用于代码补全以及代码和语言的理解和生成。
Code Gemma 7B Instruct 是在Code Gemma 7B。基础之上进行了指令微调,非常适用于开发对话式AI机器人,尤其是代码、编程或数学推理主题的对话。
为了提升Code Gemma的推理能力,开发人员在多个数学数据集上进行监督式微调,包括来自竞赛的12,500个具有挑战性的数学问题、8,500个小学数学问题、大规模的数学文字问题数据集等,以及用于提高解决长代数问题能力的合成数据集。
Code Gemma测试数据
开发人员在多个知名测试平台中对Code Gemma进行了多维度的测试,皆取得了不错的成绩。
通过HumanEval Infilling平台测试了Code Gemma的CodeGemma的代码补全能力,结果显示,Code Gemma 2B表现出色,与其他FIM感知代码模型相比,在推理速度上快了近2倍,同时保持了更好的代码补全质量。
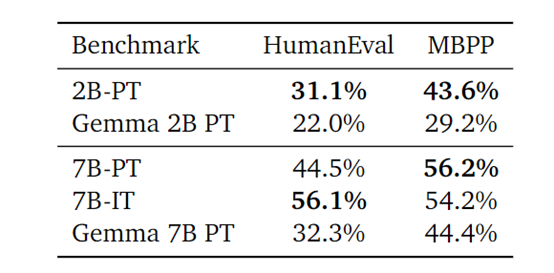
在Python编码方面,Code Gemma使用了HumanEval和MBPP测试平台。结果显示,CodeGemma 7B预训练基础模型和指令微调两款模型,均优于Gemma基础模型,并且在在Python编程任务上效果更好。
多语言编程方面,CodeGemma使用了Babel Code测试平台,结果显示,Code Gemma在多种流行的编程语言上都展现出了强大的编码能力,包括C/C++、C#、Go、Java、JavaScript、Kotlin、Python和Rust等。
尤其是在Java、JavaScript和Kotlin等语言上,Code Gemma的指令微调版本效果非常好。
本文素材来源谷歌官网,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



