英特尔重磅发布Gaudi 3芯片:将进入中国,比H100强50%!
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
全球芯片领导者英特尔在“Vision 2024”大会上,重磅发布了专用于生成式AI训练、推理的芯片——Gaudi 3。
根据英特尔官方公布的测试数据显示,在Llama-2 7B/13B和GPT-3 175B大模型的训练中,Gaudi 3的训练时间平均比英伟达的H100缩短了50%。
在Llama-2 7B/70B以及Falcon180B大模型的推理测试中,Gaudi 3的吞吐量平均比H100快了50%,平均推理效率快了40%;即便与H200相比,推理效率也快了30%,这是一块性能非常强劲的AI芯片。
目前,英特尔已与戴尔、联想、惠普等著名厂商达成了战略合作,将于2024年第二季度陆续提供该芯片。但由于美国官方限制,英特尔会在6月和9月提供“中国版”Gaudi 3系列芯片。
Gaudi-3白皮书:https://www.intel.com/content/www/us/en/content-details/817486/intel-gaudi-3-ai-accelerator-white-paper.html
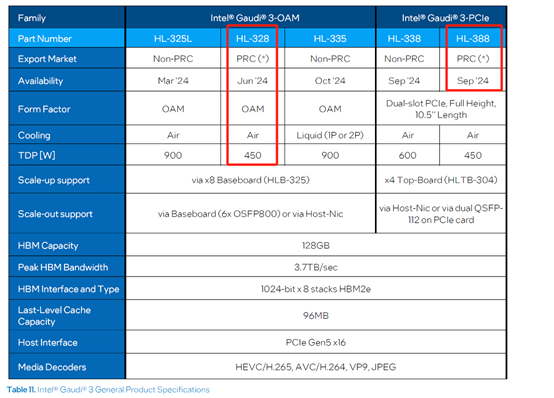 即将在中国发售的两款特制Gaudi 3系列芯片
即将在中国发售的两款特制Gaudi 3系列芯片
Gaudi 3特色功能介绍
随着ChatGPT的持续火爆出圈,参与生成式AI赛道的选手越来越多,包括众多世界500强以及政务机构等。各行业对大模型的训练、推理需求越发旺盛,所以,Gaudi 3的整体架皆根据大模型的需求来设计。
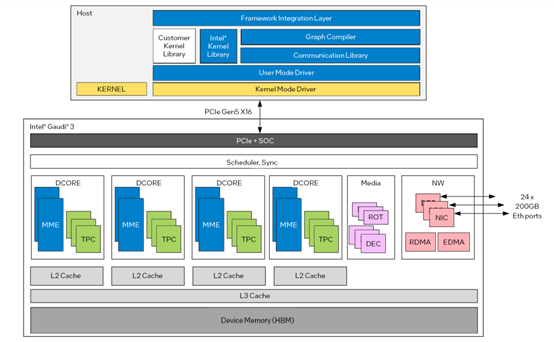
据悉,Gaudi 3采用的是5纳米工艺制造,为了满足庞大的算力需求,允许并行激活所有引擎,包括矩阵乘法引擎(MME)、张量处理器核心(TPC)和网络接口卡(NIC)等,主要特色功能如下。

生成式AI专用计算引擎:Gaudi 3的每个加速器都具有独特的异构计算引擎,由64个AI定制和可编程TPC和8个MME组成。
每个Gaudi 3的MME都能够执行强大的64,000个并行运算,从而实现高度的计算效率,使其擅长处理复杂的矩阵运算,这是深度学习算法的重要基础计算类型。
这种独特的设计加快了并行AI操作的速度和效率,并支持多种数据类型包括FP8和BF16。
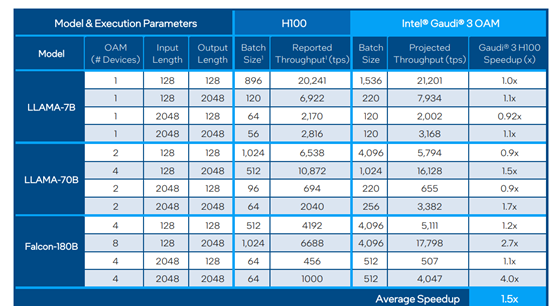 Gaudi 3与H100测试对比数据
Gaudi 3与H100测试对比数据
满足大模型超高内存需求:Gaudi 3拥有128GBHBMe2内存容量、3.7TB内存带宽和96MB板载静态随机存取内存,这可以满足大模型的超大内存需求,尤其是可生成图片、音频、视频的多模态功能,可节省大量数据中心成本。
企业级生成式AI扩展:Gaudi 3集成了24个200Gb以太网端口,并提供灵活、开放标准的网络传输。可帮助企业从单个节点纵向扩展至数千个节点,极大满足高并发的大型集群需求。
全新设计的PCIe:为了性能降低功耗,英特尔全新设计了Gaudi 3的PCIe,功率只有600w,内存容量为128GB,带宽为每秒3.7TB。
这对于模型微调、推理和RAG(检索增强生成)等很有帮助。
RoCEv2:Gaudi 3支持RoCEv2协议的扩展,包括对MPI集体操作的映射、基于时间的拥塞控制、多路径负载均衡等,这些特性对于提高网络通信的效率和可靠性非常有帮助。
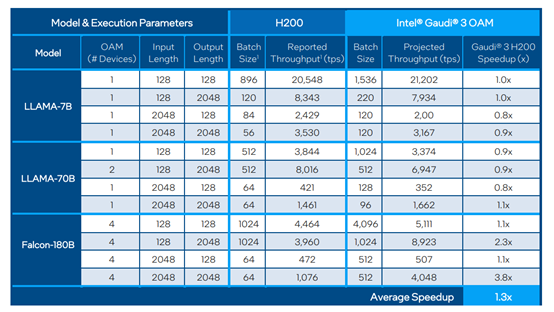 Gaudi 3与H200测试对比数据
Gaudi 3与H200测试对比数据
完美适配开发环境:为了发挥Gaudi 3的性能,英特尔搭建了专业用于开发大模型的环境,例如,集成了PyTorch框架,针对HuggingFace社区上主流开源大模型进行了适配等,这可以帮助开发人员加速大模型的开发、训练进程,并能实现跨硬件环境的模型移植。
构建企业级生成式AI开放平台
除了发布强劲的Gaudi 3芯片之外,还在积极布局软件生态。
目前,英特尔已与Anyscale、Articul8、DataStax、Domino、Hugging Face、KX Systems、MariaDB、MinIO、Qdrant、RedHat、Redis、SAP、VMware、Yellowbrick等知名企业达成了技术合作,希望为企业构建一个开放、高效的生成式AI开放平台。

旨在开发多元化、企业级的生成式AI产品,并通过RAG实现一流的易于部署、性能和价值。
使企业在云上运行的大量专有数据,能够通过开放的大模型、RAG得到全面增强和利用,从而加速生成式AI在企业中的场景化落地。
本文素材来源英特尔官网、白皮书,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



