2万亿训练数据,120亿参数!开源大模型Stable LM 2-12B
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
4月9日,著名大模型开源平台Stability.ai在官网开源了,全新类ChatGPT模型Stable LM 2 12B。
据悉,Stable LM 2 12B有120亿参数,使用了英语、西班牙语、德语等7种语言2万亿tokens的训练数据。一共有基础模型和指令微调两个版本,能生成文本、代码等内容,还能作为RAG的核心来使用。
同时,Stability.ai还对之前发布的模型Stable LM 2 1.6B进行了更新,尤其是在硬件需求方面进行了大幅度优化。所以,这两款模型非常适合小企业、个人开发者使用。其性能也超过了Qwen1.5-14B-Chat、Mistral-7B-Instruct-v0.2等知名开源同类小参数模型。
12B开源地址:https://huggingface.co/stabilityai/stablelm-2-12b
1.6B新版本:https://huggingface.co/stabilityai/stablelm-2-1_6b-chat
技术报告:https://arxiv.org/abs/2402.17834
在线demo:https://huggingface.co/spaces/stabilityai/stablelm-2-chat

StableLM 2架构介绍
Stable LM 2 12B/1.6B皆使用的是Transformer架构,一共24层、32个自注意力头,并使用大量公开且多样化大约2万亿tokens的数据集进行了预训练。
这些数据包括Arxiv、PubMed、S2ORC、PhilPapers等学术论文数据集,以及BookCorpusOpen、PG-19、FanFics等图书和小说数据集。
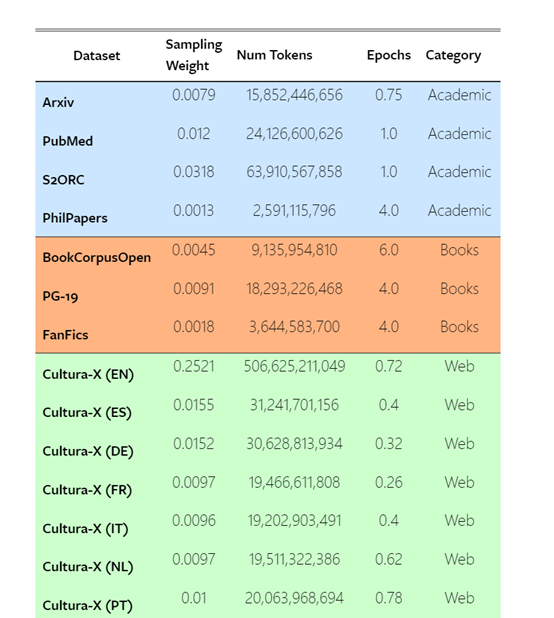
Stability.ai还使用了来自Web的数据集,如Cultura-X、OpenWebText2、RefinedWeb等,以及来自社交媒体和法律领域的数据集。
此外,每个数据集都有相应的权重,为每个数据集提供了详细的统计信息,包括标记数量、训练时长等。还使用了一种创新的分词技术,对原始分词器进行了扩展,以便更好地压缩代码和非英文语言数据。
训练策略方面,Stability.ai使用了一种称为“FlashAttention-2”的高效序列并行优化技术,以4096的上下文长度从头开始训练StableLM 2。同时训练过程中采用BFloat16混合精度,并使用标准的AdamW优化器进行训练。

模型微调阶段,Stability.ai使用了监督微调(SFT)、直接偏好优化(DPO)和自我知识学习三种方法,对生成的文本进行排序,然后使用排序结果来调整模型的参数,使其生成更符合人类偏好的文本。
StableLM 2测试数据
Stability.ai将两款StableLM 2 模型在ARC、HellaSwag、MMLU、TriviaQA、Winograd、GSM8K等知名测试平台上进行了综合测试。
零样本和少样本基准测试方面,StableLM 2 1.6B在综合平均分数上获得45.3分,在1.6B以下模型中名列前茅,但仍低于一些更大的模型如phi-2和stablelm-3b-4e1t。
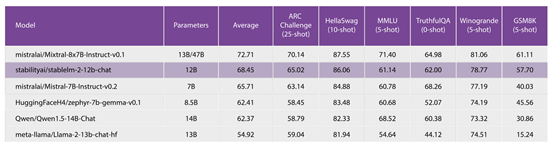
而Stable LM 2 12B的性能超过了Qwen1.5-14B-Chat、Mistral-7B-Instruct-v0.2等模型,略低于mistralai/Mixtral-8x7B-Instruct-v0.1。
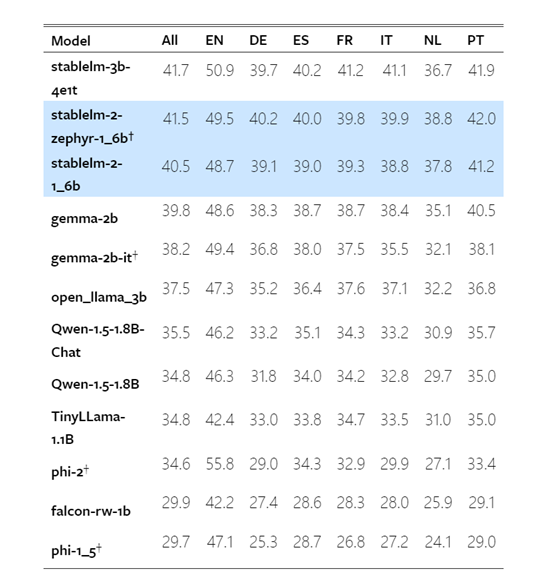
多语言基准测试:StableLM 2 1.6B在不同语种任务上的表现都很出色,在所有语种的综合分数为40.5分,在英语任务上得分48.7分、德语39.1分、西班牙语39.0分等。
多轮对话基准测试:StableLM 2 1.6B与其他模型在MT-Bench多轮对话任务上进行了深度对比。StableLM 2 1.6B的综合得分与规模明显更大的模型如Mistral-7B和MPT-30B不相上下,在某些指标上甚至获得了更高的分数。
本文素材来源Stability.ai官网,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



