文本生成3分钟44.1 kHz 音乐,Stable Audio 2.0重磅发布!
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
4月4日,著名开源大模型平台Stability.ai在官网正式发布了,音频模型Stable Audio 2.0。
Stable Audio 2.0支持用户通过文本或音频,一次性可生成3分钟44.1 kHz的摇滚、爵士、电子、嘻哈、重金属、民谣、流行、乡村等20多种类型的高质量音乐。
其生成音乐的时长也超过了谷歌的Music-fx、Meta的AudioCraft等知名产品。目前已正式开放,免费提供试用(没锁区直接登录)。
体验地址:https://stableaudio.com/generate

Stable Audio 2.0简单介绍
2023年9月14日,Stability.ai首次发布了Stable Audio 1.0,主要有免费和付费两个版本。但无论是免费还是付费最长只能生成90秒的音乐。
2.0版本能极限延长音乐时间,主要是因为Stability.ai使用了Diffusion transformer (DiT)替换了1.0的U-Net架构。即将发布的Stable Diffusion 3也使用了类似的技术,使其生成图像的质量、文本语义还原得到了极大增强。
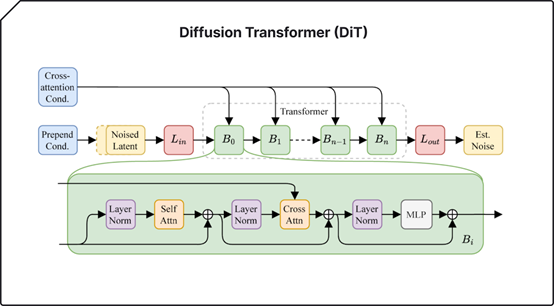
DiT能将随机噪音逐步细化为结构化数据,识别出复杂的模式和关系。而自动编码器可压缩音频并将其重建为原始状态,能捕捉并再现基本特征,同时过滤掉不太重要的细节,从而生成更加连贯的声音。
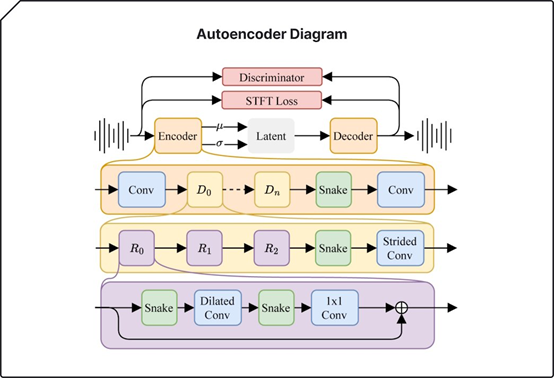
所以,将DiT与自动编码器相结合,能够处理更长的音频序列,并准确地解读、还原用户输入的提示文本。
此外,Stable Audio 2.0使用了一个超过80万个音频文件组成的数据集,包含音乐、音效以及各种乐器。
该数据集总计超过1.95万小时的音频,同时与知名音乐服务商AudioSparx进行合作,所以,生成的音乐可以用于商业化。
Stable Audio 2.0案例展示
根据「AIGC开放社区」的使用体验,虽然Stable Audio 2.0生成的音乐时间变长了,但是生成的效率比1.0版本显著提升,平均生成一个3分钟音乐在1分钟左右。下面是真实使用案例展示。
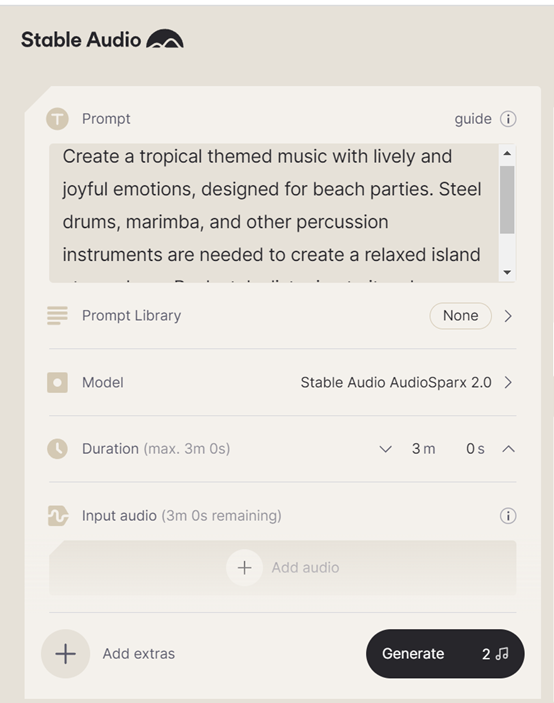
例如,我们生成一个用于冥想的音乐,输入提示词:一段宁静和平的禅意冥想背景音乐,应该能够帮助人们放松和内省。这首音乐应该包含流水的声音、柔和的风铃,以及长笛的轻轻吹奏,用D大调和缓慢的节奏来营造出自然和宁静的氛围。
模型我们选择Stable Audio 2.0,时长就是3分钟,辅助音频不用选择,然后点击“Generate”生成。
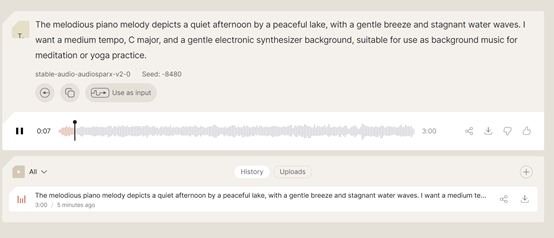
不到1分钟的时间就生成好了,我们可以选择在线试听,也可以下载下来使用。
本文素材来源Stability.ai官网,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



