微软开源创新LoRA组合方法,增强文生图复杂细节控制
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
LoRA(低秩适应)的高效能力已在文生图领域获得广泛应用,可以准确渲染、融合图像中的特定元素,例如,不同字符、特殊服装或样式背景等,同时可对图像进行压缩、去噪、补全进行优化操作。
但想在模型中应用多个LoRA构建更复杂的图像时,会出现图像失真、难以控制细节的难题。因此,微软和伊利诺伊大学的研究人员开发了Multi-LoRA Composition(多重 LoRA 组合方法)。
该方法包括LoRA Switch和LoRA Composite两种,无需微调就能集成多个LoRA一起使用,并且能保持每个LoRA 的权重完整性。
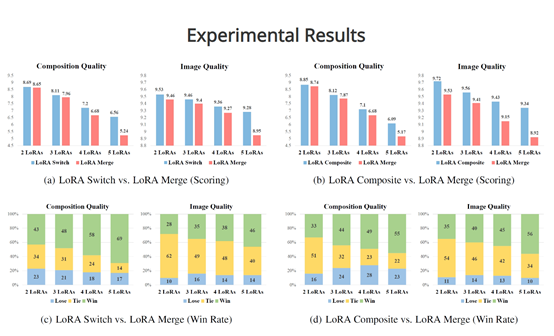
研究人员使用GPT-4V对该方法进行了综合评测,结果显示,LoRA Switch 在图像合成质量方面表现出卓越的性能,而 LoRA Composite 在图像质量生成方面表现出色,并且随着LoRA数量的增长效果将更明显。
论文地址:https://arxiv.org/abs/2402.16843
Github地址:https://github.com/maszhongming/Multi-LoRA-Composition
项目地址:https://maszhongming.github.io/Multi-LoRA-Composition/
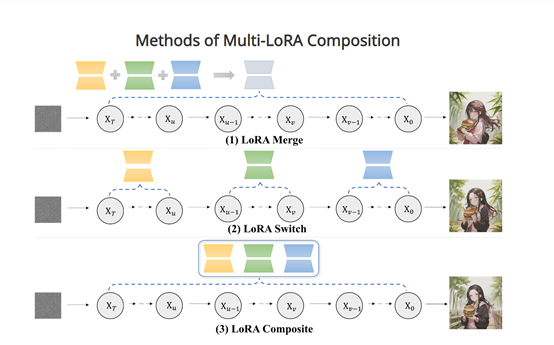
LoRA Switch
LoRA Switch的技术原理是在每一个消噪步骤中, 选择性地激活一个LoRA模型,同时在多个LoRA模型之间轮流切换,确保每个元素都能得到充分的渲染。
LoRA Switch主要由3大块组成:1)扩散模型,用于生成图像的基模型,并执行顺序消噪的过程;2)多个LoRA模型,每个LoRA模型专门渲染图像中的一个元素,例如,人物、服装、背景、风格等;
3)切换功能,用户控制在消噪步骤中,按需激活每一个LoRA模型。
LoRA Switch的底层运行机制包括:首先设置LoRA模型的激活顺序,如先后激活人物LoRA、服装LoRA、风格LoRA等。
然后从第一个LoRA模型开始生成图像,每隔N个消噪步骤就切换激活下一个LoRA。当切换完所有LoRA后,再从头开始新的一轮切换,直到图像最终生成。
例如,在虚拟试穿场景中,LoRA Switch会在连续的去噪步骤中轮换角色LoRA和服装LoRA,从而确保每个元素都以精确和清晰的方式呈现。
LoRA Switch可以确保每个元素都得到充分渲染,避免了直接融合LoRA权重矩阵时出现的不稳定问题,也可以灵活调整LoRA之间的切换速率,适应不同的场景。
LoRA Composite
LoRA Composite的技术原理是在每个消噪步骤计算每个LoRA的无条件和有条件分数估计。然后对这些分数进行平均,作为图像生成过程的指导。这样可以极大平衡不同LoRA的作用,实现更协调的成像合成。
LoRA Composite主要包括2大块:1)扩散模型,用于执行去噪流程;2)多个LoRA模型:对扩散模型的参数进行适应,每个LoRA负责渲染一个元素。
LoRA Composite在运行时,首先计算每个LoRA模型的无条件和条件分数估计,然后对所有LoRA模型的分数进行平均,得到一个综合分数。以这个综合分数作为指导,驱动扩散模型执行顺序消噪过程并逐步生成图像。
与LoRA Switch不同的是,LoRA Composite综合了所有LoRA,并直接影响扩散过程,而不是操纵权重矩阵。

LoRA Composite可以集成任意数量的LoRA,并突破了目前研究中通常只合并两个LoRA的技术限制。
评估数据集
研究人员还开发了首个面向LoRA组合图像生成的专业测试基准ComposLoRA。该基准包含6大类、22个LoRA模型,480个组合样本,可以全面评价不同的LoRA组合。
实验结果表明,在保证图像质量的同时,新提出的两种组合方法相比目前主流的LoRA融合技术,可以实现更协调、逼真的多元素图像生成效果。尤其是使用数量较多的LoRA组合时,生成高质量的效果更加明显。
本文素材来源Multi-LoRA Composition论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



