谷歌推出通用AI代理:能自动执行600多种动作,游玩复杂3D游戏
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
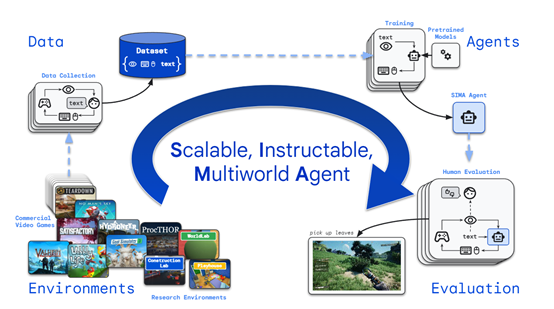
谷歌DeepMind的研究人员推出了一种面向3D环境的通用AI代理——SIMA。
SIMA无需访问游戏的源代码,也不需要定制的API。只需要输入图像和用户提供的简单自然语言文本指令,SIMA就能像人类玩家一样执行走路、跑步、建造、打开地图等各种游戏中的操作。
为了测试、训练SIMA的性能,研究人员与8个游戏工作室合作,在《无人深空》、《模拟山羊3》、《Teardown》、《挖矿模拟器》等知名复杂3D游戏上进行了综合测试。
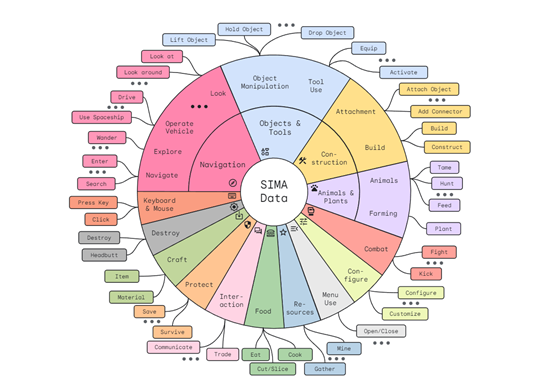
结果显示,用户只需要在游戏中提供简单的文本、图像提示,SIMA就能执行挖矿、开飞船、制作装备、打开外骨骼、搜集任务、爬楼梯等600多种基本操作,每个动作可以在大约10秒内完成。
技术报告:https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/sima-generalist-ai-agent-for-3d-virtual-environments/Scaling%20Instructable%20Agents%20Across%20Many%20Simulated%20Worlds.pdf

在游戏场景中测试AI代理是一个重要课题,与传统的沙盒2D方法不同的是,SIMA选择了操作、环境、视觉难度更高的3D游戏。
SIMA使用了大模型的训练方法,通过广泛的数据分布来识别那些复杂的动作,同时无需为每个新游戏设计特定的控制、观察模块,就能理解人类的文本指令,并将其转化为具体的行动。
多种大模型组成的“人体”
从SIMA的总体架构来看,由多种大模型组合而成像是在模仿人体。视觉感知模型充当“眼睛”、大语言模型充当“大脑”、建模规划模型充当“思维”、控制和执行模型充当“四肢”。
也就是说SIMA在接收到指令后,会用人的方式去思考、规划接收到的任务,然后再去执行。
视觉感知模型:视觉感知模块负责处理AI代理的图像观察,并提取关键信息以辅助语言指令的理解和环境的交互。该模块使用卷积神经网络(CNN)等深度学习技术对输入的图像数据进行处理和特征提取。
使得SIMA能够识别和分析图像中的物体、场景和空间位置等重要信息,以帮助AI代理更好地理解语言指令,并在虚拟世界中进行准确的交互和操作。

大语言模型:主要负责解析和理解输入的自然语言指令。使用了NLP、词嵌入、序列模型和注意力机制等技术,将语言指令转化为机器可理解的表示。
使得AI代理能够准确地理解和解释指令中的动作和目标,为后续的建模和规划提供基础。
建模规划模型:通过强化学习和规划算法,与环境的交互和反馈来学习最佳的行动策略。AI代理通过不断尝试和优化,逐渐掌握了在不同环境下执行任务的能力。
可根据语言指令、视觉感知信息和当前环境状态,生成有效的动作序列,以实现任务的完成。
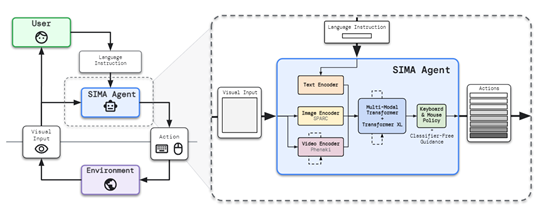
控制和执行模型:主要负责将生成的动作序列转化为实际的动作控制指令,并映射到键盘、鼠标上,以驱动AI代理在3D游戏中执行任务,例如,移动、跳跃、奔跑、挖矿等,同时可根据环境的反馈进行自适应调整和优化。
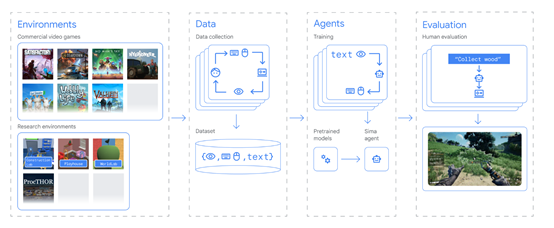
数据收集和预处理
数据收集和预处理是SIMA的核心模块之一,主要获取、准备和处理用于训练和评估AI代理的数据。
研究人员从商业游戏等环境搜集了海量数据,搜集完成后对数据进行了清洗、转换和标准化数据操作,方便后续的训练和分析。
数据清洗:对原始数据进行去噪和异常值处理,可能会存在一些噪声或异常数据,例如,图像中的视觉干扰或语言指令中的错误字符。研究人员通过采用图像去噪和文本纠错的方式,来消除这些干扰因素。
数据转换:在进行训练之前,需要将原始数据转换为机器可处理的格式。图像数据,可以使用图像处理技术进行特征提取或缩放操作,以便于模型的训练和推理;
文本数据,可以进行词汇化、分词和编码等处理,将其转换为数值表示形式输入到深度学习模型中。
数据标准化:为了确保数据的一致性和可比性,需要对数据进行标准化处理。包括对图像进行归一化或标准化,以使其具有相似的亮度、对比度和颜色分布。对于文本数据,可以进行词干化、停用词移除和词向量化等操作。
经过一系列数据清洗、转换、标准化后,可以帮助SIMA更好地去学习游戏中的物体、动作、交互等,从而提升整体的动作指令准确率。
研究人员表示,未来,会持续迭代SIMA的通用代理能力,希望可以在实际生活中帮助用户做更多的事情。
本文素材来源谷歌SIMA论文,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



