图片直接生成3D视频模型,开源Stable Video 3D来啦!
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
3月19日,著名大模型开源平台stability.ai在官网开源了,图像直接生成3D视频模型——Stable Video 3D(以下简称“SV3D”)。
这与其之前发布的Stable Zero123、Zero123XL模型相比,SV3D在生成质量、多视角、泛化能力、3D建模、一致性、光照效果等方面实现大幅度提升。
SV3D一共有两个版本:SV3D_u,支持单个图像生成轨道视频,无需相机调节;
SV3D_p扩展了 SVD3_u 的功能,支持单个图像和轨道视图,从而可以生成沿特定的摄像机路径创建 3D 视频。
huggingface地址:https://huggingface.co/stabilityai/sv3d
github地址:https://github.com/Stability-AI/generative-models?tab=readme-ov-file
论文地址:https://stability.ai/s/SV3D_report.pdf
长期以来,用单张图像重建3D物体模型一直是计算机视觉领域的一大挑战。传统的3D重建方法是,需要从多个角度拍摄目标物体的照片,再通过复杂的算法进行3D建模,整个过程费时、费力并且效果也不理想。

而SV3D借助了视频扩散模型在时间连贯性、特征/轨迹识别的诸多优势,将其应用在物体的空间上3D一致性视图,进而快速获得3D物体信息,达到3D模型重建的卓越效果。
多视角合成和模型改良
SV3D核心模块之一,基于其自研的Stable Video Diffusion(简称SVD)视频模型之上。
为了达到理想的3D模型重建,研究人员对SVD进行了性能改良:U-Net网络骨干保持不变,由多层3D卷积和Transformer注意力模块构成,同时将输入图像的CLIP嵌入作为附加条件输入到Transformer注意力模块中;
移除了原SVD中控制帧率和动作的条件输入,因为这些对静态物体合成无任何帮助;在每个残差块中,将相机轨迹的仰角和方位角嵌入与噪声时间步长进行拼接后输入。
这种巧妙的技术重构,使得模型不仅可利用条件图像进行像素级推理,还能结合显式的相机姿态来控制生成的视角。同时可通过视频模型在时序上学习到的一致性知识,来指导在空间上生成物体的一致多视图。
相机轨迹功能
为了扩展模型的多种生成能力,SV3D设计了两种类型的相机轨迹作为条件输入,
静态轨迹:相机在物体水平面内环绕方位角均匀分布,仰角固定为条件图像的仰角。但这种设置的缺陷可能会遗漏物体的顶部或底部视图。
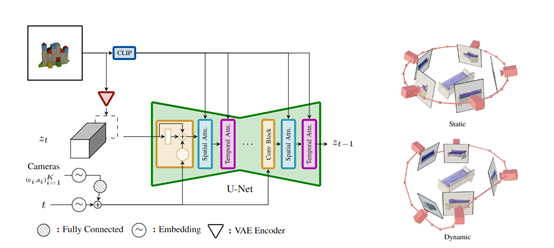
动态轨迹:从静态轨迹出发,对方位角加入少量噪声,对仰角加入平滑的随机正弦波,使相机在垂直方向也能环绕物体,可充分展现物体的全貌。
这种双轨迹生成设计,突破了传统的生成3D模型视角的局限性,并显著提高了多视图的一致性、细节还原和控制性。
3D模型优化
为了提升模型生成内容的一致性、精细程度、质量等,SV3D采用了从“粗”到“细”的优化策略。
粗优化:首先利用多视图渲染结果对Instant NGP框架中的NeRF模型进行优化,得到物体的初始粗糙几何形状和体积密度场。
研究人员在粗优化中设计了”遮罩分数”的损失函数。多视图渲染结果中无法看到的部分,会将相应的像素排除在损失函数的计算中避免被视为噪声,可以让模型专注学习可见区域。
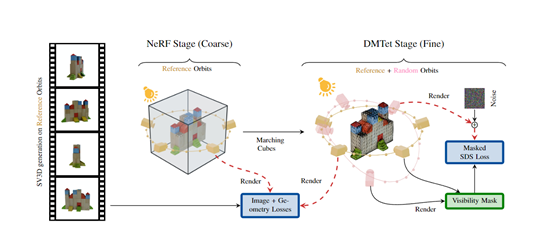
细优化:在得到粗糙的NeRF模型后,使用另一种神经表示DMTet来进行细节优化。DMTet兼有体数据结构和网格表面的优势,能高效表达细节丰富的几何结构和纹理,可以重新利用多视图渲染结果以及之前训练的NeRF预测作为精细优化目标。
SV3D实验数据
研究人员在GSO、OmniObject3D等数据集上评估了,SV3D对静态轨迹和动态轨迹视频的生成能力。他们将生成了对应真实相机轨迹的视频,并将每一帧与地面真实帧进行对比,计算感知相似度、峰值信噪比、结构相似性等多种指标,全面评估视频质量和多视角一致性。

与Stable Zero123、Zero123、EscherNet等模型相比,SV3D在所有评估指标上都展现出卓越表现,能生成更高分辨率、细节更丰富、与输入图像更加贴合、多视角更加一致的视频。
本文素材来源stability.ai官网,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



