极大降低大模型训练内存需求,Meta等推出高效方法
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
目前,多数大模型具备生成图像、视频、音频等多模态功能,但在预训练的过程中对内存的需求越来越高,例如,消费级显卡根本无法满足训练要求,对于个人、小型企业来说非常不方便。
MetaAI、加州理工学院、卡内基梅隆大学等研究人员,联合推出了一种高效训练方法GaLore。相比传统的LoRA(低秩适应)优化方法,GaLore通过在训练过程中梯度矩阵自然呈现的低秩结构,可大幅降低30%优化器状态的内存需求,同时保留完全参数的学习能力。
研究人员在LLaMA 1B、7B模型上对GaLore进行了综合测试。结果显示,相比全精度基线,减少了90%的优化器内存开销,而性能只下降了1%左右。
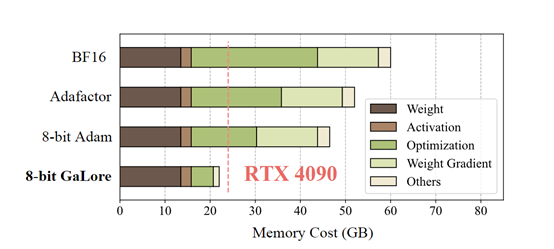
值得一提的是,在使用8-bit GaLore优化方法后,仅使用单张4090(24G内存)消费级显卡便原生完成了LLaMA 7B模型的预训练,不需要任何模型并行、梯度校验或内存卸载等技术支持。
论文地址:https://arxiv.org/abs/2403.03507

低秩结构分析
首先研究人员证明了在某些条件下,梯度矩阵G在训练过程中会自然呈现出低秩结构,这为GaLore的算法提供了重要理论基础。
在训练过程中,权重矩阵的梯度往往呈现出低秩结构。对于某些梯度形式和相关的神经网络架构,梯度矩阵在训练过程中会逐渐趋向于低秩。
例如,在可逆神经网络中,每一层的梯度矩阵都可以表示为特定的矩阵乘法形式,随着训练的进行,这种形式的梯度矩阵会收敛到秩为1的低秩矩阵。同样,对于损失函数,研究人员也推导出了类似的低秩结构。
梯度低秩投影
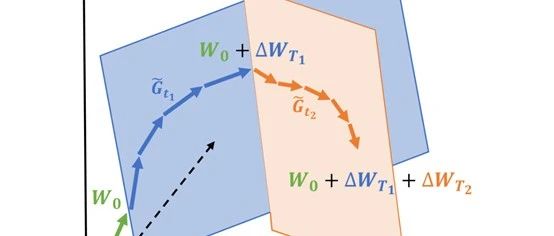
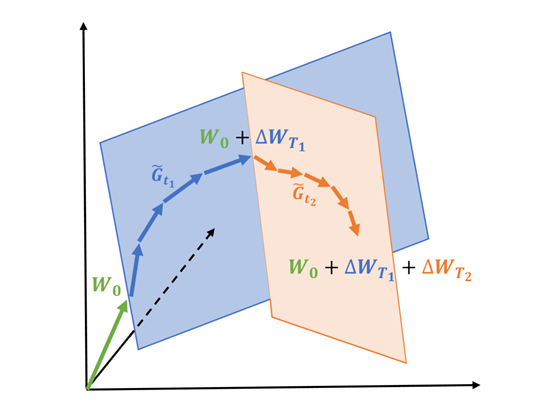
基于低秩结构分析的理论,研究人员开发了GaLore, 其技术创新通过权重矩阵梯度的缓慢变化的低秩结构,而不是试图将权重矩阵本身近似为低秩形式。GaLore通过计算两个投影矩阵P和Q,将权重矩阵梯度G投影到低秩形式P⊤GQ。
这样,依赖于分量梯度统计的优化器状态的内存成本可以大大降低。定期更新P和Q(例如,每200个迭代)也只会产生最小的额外算力成本。
此外,研究人员进一步分析了在固定投影矩阵P和Q的情况下,GaLore的收敛性。他们充分证明了当梯度满足特定形式时,如果选择合适的P和Q投影到主成分子空间,那么GaLore的训练是收敛的,当P和Q应该投影到梯度相关矩阵的最大特征子空间时,能实现更快的收敛速率。
GaLore比LoRA更有优势
LoRA作为一种高效的优化方法,已经被广泛应用在大模型训练领域。研究人员指出,GaLore比LoRA更出色,能节省30%左右的内存,同时具备以下3大优势。
完整参数学习:GaLore允许进行完整参数学习,而不像LoRA那样限制了参数搜索空间。
LoRA通过在每一层中添加一个低秩矩阵来减少可训练参数和优化器状态的数量。但这种限制参数搜索空间的方法可能导致在预训练和微调阶段的性能下降。

相比之下,GaLore通过低秩投影模块将梯度矩阵投影到低秩空间,实现了完整参数学习,从而更好地保持了模型性能。
内存占用更少:GaLore通过将梯度矩阵投影到低秩空间,大大降低了优化器状态的内存占用。
而LoRA在每一层中引入了额外的低秩矩阵参数,这会增加内存占用。所以,GaLore在相同模型和数据集下可以实现更低的内存占用。
保持模型性能:相比LoRA,GaLore通过低秩投影模块实现内存占用的降低,但并不改变训练动态和模型的收敛性。
GaLore在大规模数据集和复杂模型上进行了实验证明,其在预训练和微调阶段的性能与使用完整秩权重进行训练几乎差不多。
本文素材来源GaLore论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



