文本生成4K超高清图像,华为等推出创新模型PixArt-Σ
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
华为诺亚方舟实验室、大连理工大学和香港大学的研究人员,推出了文本生成4K超高清图像的模型——PixArt-Σ。
与上一代PixArt-α相比,PixArt-Σ在图像质量/细节、训练效率、文本语义理解/还原等方面实现了大幅度提升。
尤其是训练效率,PixArt-Σ基于DiT架构(Diffusion Transformer)并提出了一种高效的注意力模块来压缩Key和Value,再通过局部聚合关键字和值的组卷积和特殊的权重初始化方案。
使得PixArt-Σ不仅能生成4K分辨图像,在训练、推理比SDXL、SD Cascade等模型更高效。
论文地址:https://arxiv.org/abs/2403.04692
项目地址:https://pixart-alpha.github.io/PixArt-sigma-project/

PixArt-Σ的核心技术在于提出了一种”从弱到强”(Weak-to-Strong)的训练方法。通过将高质量的训练数据融入到其前作PixArt-α的预训练基础上,再结合高效Tokens压缩注意力模块,PixArt-Σ成功实现了从弱模型到强模型的高效演化。
高效Tokens压缩注意力
传统的自注意力机制在处理像素级别的Tokens时,计算复杂度会呈指数级增长,这给文生4K图像带来了巨大挑战,而高效Tokens压缩注意力机制可以很好解决这一难题。
其设计思路是,在自注意力机制的Query(Q)、Key(K)和Value(V)之中,只对K和V进行压缩,保留了所有的Q。依据是,Q主要用于捕获精细的像素级信号,而K和V则承载了更高层次的语义信息,所以比较适合进行压缩。
为了实现K、V压缩,PixArt-Σ采用了2×2的步长卷积核对邻近区域进行局部聚合操作。该操作将相邻的2×2个K(或V)Token合并压缩为1个Token,从而将K和V的总量减少到原来的1/4,大幅降低了计算复杂度。
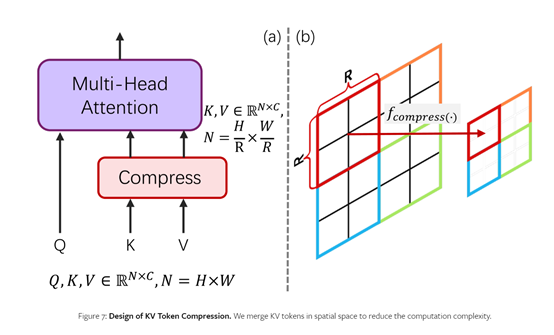
同时为确保模型可以从之前的PixArt-α平滑过渡到PixArt-Σ,研究人员提出了”Conv Avg Init”(卷积平均初始化)权重初始化方案。
该方案将2×2的卷积核初始化为平均卷积,可以在不做任何调整的情况下,让K、V压缩模块最初就能产生较为粗糙但接近正确的结果,从而加速后续的微调流程。
在高效Tokens压缩注意力的帮助下,PixArt-Σ在生成4K图像时,训练和推理的时间缩减了34%左右极大节省了AI算力。
从弱到强训练方法
训练方法方面,如果直接从低分辨率过渡到4K分辨率,模型可能难以快速适应,影响训练效率。PixArt-Σ则使用了从弱到强的训练策略:1)先从256×256的低分辨率着手,通过80K步的训练,让模型对齐文本和图像特征;

2)再以512×512为中介,经过10K步训练,过渡到1024×1024分辨率;3)最后在此基础上通过2K步的训练,最终实现了对2K和4K分辨率的支持。
这种分阶段、循序渐进的策略,避免了分辨率突然升高带来的适应性困难。
值得一提的是,PixArt-Σ在过渡到更高分辨率时,借助了”位置嵌入插值”技术,将低分辨率模型的位置嵌入升采样到高分辨率,作为初始化进一步加速了模型的效率。
高质量训练数据集
为了提升PixArt-Σ生成图像的质量和多样性,研究人员搜集了一个一个包含3300万张高分辨率图像的内部数据集Internal-Σ,比之前的数据集大了一倍还多。
Internal-Σ数据集中,所有图像的分辨率均高于1K,其中还特别收录了230万张4K分辨率的图像。这些高分辨率图像不仅扩大了PixArt-Σ生成的风格,还能为模型学习生成4K图像的真实数据分布提供必要的素材。

此外,为了精准还原用户的文本语义提示,研究人员弃用了之前的PixArt-α使用的LLaVA,采用了更强大的Share-Captioner模型来生成详细准确的图像文本描述。
同时,扩大了文本编码器可处理tokens长度至300词,使文本描述能更丰富详细,提高文本与图像的语义对齐能力。
PixArt-Σ生成图片展示
以下是研究人员公布PixArt-Σ的生成图片案例,在质量、细节、语义还原等方面非常优秀。
一个华丽的珊瑚礁纸艺世界,充满了色彩缤纷的鱼类和海洋生物。

模特特写照片,朦胧光影,激光金属发饰,柔和美丽,浅金色瞳孔,白色睫毛,低饱和度,真实皮肤细节,毛孔细纹清晰,光反射折射,超清,电影摄影、获奖作品。

乐高模型,未来火箭站,复杂细节,高分辨率,虚幻引擎,超高清。

本文素材来源PixArt-Σ论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



