专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
阿里巴巴集团AI研究院推出了一款创新性视频模型——EMO。
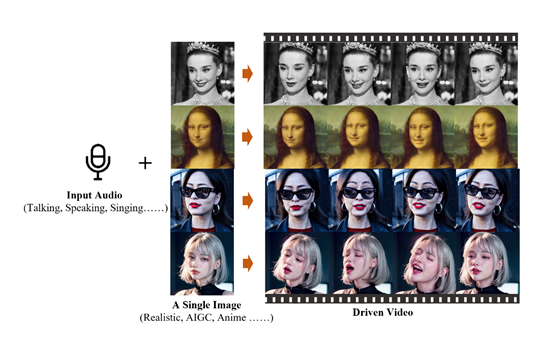
用户只需要向EMO提供一张图像、一段音频,就能生成任意时长表情丰富的视频。例如,提供一个张国荣的图像和一首歌曲,就能让其唱歌。
从EMO生成的视频来看,人物嘴型和背景音乐的契合度非常高,表情也非常丰富人物仿佛像“活”了一样,整体效果非常不错。
论文地址:https://arxiv.org/abs/2402.17485
项目地址:https://humanaigc.github.io/emote-portrait-alive/
阿里研究人员展现了多个EMO生成的视频,例如,“复活”赫本,让她唱一下Ed Sheeran 的《Perfect》。
除了唱歌之外,也能通过说话音频生成内容,例如,让蒙娜丽莎背诵一段莎士比亚的喜剧名作《皆大欢喜》。
其实目前有不少AI产品能做出上面展示的效果,但是有两点很难比肩EMO。一个是嘴型,语音到虚拟人物嘴形的映射非常复杂,不同的语音音素可能需要相似的嘴型,而相同的音素在不同语境下可能需要不同的嘴型表现。
此外,自然语言中的连读、强调和情感也会影响嘴型,使得完美同步更加困难。我们仔细观察一下EMO的嘴型动态效果,在停顿、高音、转音等方面可以完美契合。
另外一个就是时长,常见产品生成的时长在几分钟左右。而EMO可以生成任意时长的视频,并且表情(如皱眉、微笑、撇嘴等)的重叠度很低,也就是说可以让人物看起来更活灵活现不会感到枯燥。
但有一个小瑕疵,生成的视频人物无法改变原始姿态、空间,例如,扭转脖子、摇头等,估计以后会进行优化。
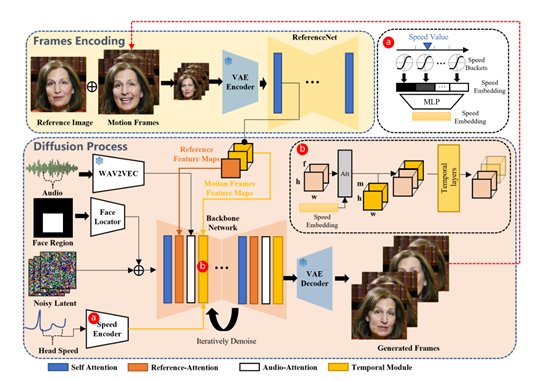
传统技术在捕捉人物表情的全谱和个体面部风格的独特性方面,存在诸多难点。而EMO以扩散模型作为核心框架,直接将音频合成为视频,从而消除了中间表示或复杂预处理的需求。
同时该方法确保视频帧之间的平滑过渡和一致的身份保持,产生高度表现力和逼真的动画效果。
主干网络:稳定控制机制,包括速度控制器和人脸定位器。这两个模块分别提供弱控制信号,调节生成视频的头部运动速度和面部位置,增强视频生成稳定性。
时间模块:使用自注意力捕捉生成序列在时域上的关系,来保证视频的流畅性,并通过塑特征维度,在时间维度上进行自注意力计算。
参考编码:该模块使用ReferenceNet提取输入人像图像的特征表示,为保持生成视频人物身份的一致性提供先验约束,与主干网络结构相似,所以两者表征空间更加兼容,方便提取的参考特征在主干网络的参考注意力层进行融合。
音频编码:通过预训练语音模型对输入音频序列进行编码,得到与视频帧对齐的音频表示序列。这里对每一帧的编码不仅包含该时刻语音信息,还结合了前后若干帧的语频表示,以建模音频对面部运动的影响。
训练流程分为图像预训练、视频训练和速度微调三个阶段。首先预训练图像生成;然后加入时序模块,学习连贯帧生成;最后仅调整速度层,避免与音频特征的关联被破坏。
训练数据方面,EMO使用了超过250小时的音频、视频素材和海量图像,涵盖中文、英文的演讲、电影和电视片段以及唱歌表演等多种内容。
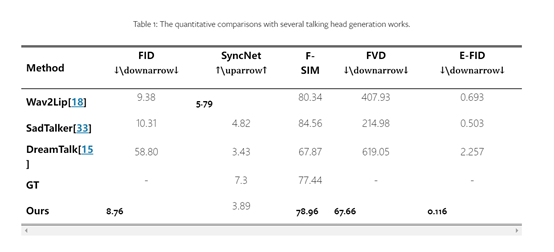
为了测试EMO的性能,研究人员在HDTF数据集上进行了综合测试。结果显示,EMO生成的视频效果超过了DreamTalk、Wav2Lip和SadTalker等目前领先的AI产品。
本文素材来源EMO论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区