200万上下文,超谷歌 Gemini 1.5!微软开源LongRoPE
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
最近,谷歌发布的Gemini 1.5最大亮点之一是支持100万tokens上下文,超过GPT-4、llma-2等开、闭源大模型。
俗话说“道高一尺,魔高一丈”,既然现在开始疯狂卷上下文,微软研究院便推出了LongRoPE框架,成功扩展至200万,超过了谷歌的输入上限。
微软研究人员在LLaMA 2、Mistral主流开源大模型对LongRoPE进行了评估。结果显示,使用LongRoPE后,各大模型保持了原始架构和性能,并对位置嵌入进行少量修改,就可以使用大部分现有的优化。
目前,微软已经宣布开源了该框架,但代码处于审核阶段,所以github页面显示错误。通过后,即可查看代码。
开源地址:https://github.com/microsoft/LongRoPE
论文地址:https://arxiv.org/abs/2402.13753

由于微调成本高、长文本稀缺以及新标记位置引入的灾难性值等原因,致使多数大模型的上下文窗口停留在128k 左右。
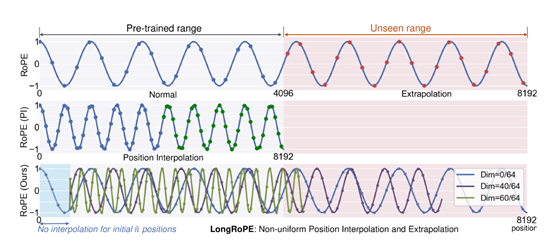
而LongRoPE通过利用位置嵌入中的两个非均匀性, 渐进式扩展策略等,突破了技术瓶颈。在保留大模型性能的前提下,极限扩展了上下文输入。
多维非均匀位置插值搜索
LongRoPE的核心模块之一,通过充分利用位置嵌入中存在的两种非均匀性,不同的RoPE维度和标记位置。
该模块会通过一个进化搜索算法来识别每个RoPE维度的最佳缩放因子。搜索空间包括每个RoPE维度的缩放因子以及位置阈值。

在控制每个维度的旋转角度的缩放比例,模型会设置一个较大的搜索范围,同时控制最初不进行位置插值的标记数量。
搜索算法主要由两个优化技术组成:1)优化的初代种群生成和单调非递减约束。前者可以利用已有的位置插值方法(比如PI、NTK等)来初始化种群;
2)后者要求生成的RoPE缩放因子在维度上保持单调非递减,这样可以大幅减少搜索代价。
这种搜索方式的好处是,可以最大限度地保留原始RoPE中的关键维度信息,从而减小位置插值带来的信息损失,为后续的微调提供更好的初始化条件。此外,在无需微调的情况下,可扩展8倍上下文窗口。
渐进式扩展训练
LongRoPE使用了一种更高效的渐进式训练策略将上下文扩展至200万,而无需直接在极长文本上进行精调。
首先使用上述搜索算法将预训练大模型扩展到25.6万,然后进行精调;接着,在精调后的模型上再次执行位置插值,最终获得200万上下文窗口,无需再进行额外精调。

这种渐进式训练策略极大减少了,AI算力资源和直接在长文本上精调的需求。此外,由于第一阶段的模型已经进行过位置插值和精调,第二阶段的RoPE搜索会更加高效。
短文本性能恢复
当大模型的上下文窗口扩展到极大值后,短文本上的性能会有所下降。为了缓解这一难题,LongRoPE使用同样的搜索算法对已经扩展的模型调整RoPE缩放因子,专门针对更短的上下文长度,例如,4000、8000进行了优化。
在推理时,如果序列长度小于8000,模型会更新为这些更短长度的RoPE因子,可以有效恢复短文本上的性能。
LongRoPE实验数据
为了测试LongRoPE性能,研究人员选择了多个长序列公开数据集进行评测,包括:Proof-pile、PG19、Books3等,覆盖从4000—200万上下文的测试范围。
基准测试集方面,使用了FFOM模型测试集,包括:ARC-Challenge、HellaSwag、MMLU等主流多任务数据集。测试任务包括困惑度评测、关键信息提取等多个子任务。
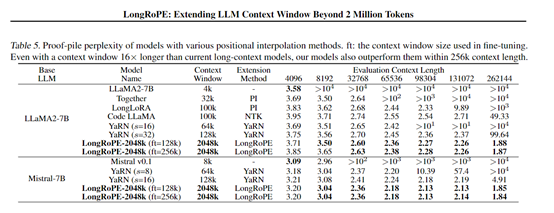
实验结果显示,通过LongRoPE扩展的LLaMA 2、Mistral开源模型的上下文,在4000——200万范围内具有较低的困惑度,实现了超过90%的密钥检索准确率;
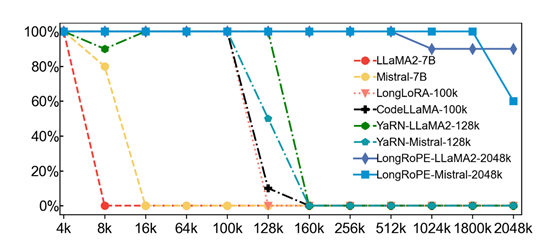
在4000上下文窗口内的标准基准测试中准确性很高,也就是说LongRoPE的短文本性能也非常棒。
本文素材来源LongRoPE论文,如有侵权请联系删除
END



本篇文章来源于微信公众号: AIGC开放社区



