Stability.ai开源全新文生图模型,性能比Stable Diffusion更强!
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
2月13日,著名大模型开源平台Stability AI在官网,开源了全新文本生成图像模型——Stable Cascade(以下简称“SC”)。
据悉,SC是根据最新Würstchen基础模型开发而成,大幅度降低了对推理、训练的算力需求,例如,训练Würstchen模型使用了约25,000小时性能却更强劲,而Stable Diffusion 2.1大约使用了200,000小时。
所以,SC的部署非常便捷适合中小企业和个人开发者,可以在4090、4080、3090等消费级GPU上进行微调。目前,SC只能用于学术研究无法商业化,未来会逐步开放。
开源地址:https://github.com/Stability-AI/StableCascade
Würstchen论文地址:https://openreview.net/pdf?id=gU58d5QeGv

自Stability AI发布Stable Diffusion系列文生图模型以来,全球已有几十万开发者使用其产品,Github超过60,000颗星,成为开源扩散模型领域的领导者。
但Stable Diffusion有一个弊端,就是对AI算力资源要求很高,不太适合普通开发者进行模型微调。所以,在提升性能的前提下又发布了新一代文生图模型SC。
Stable Cascade模型介绍
SC是基于Würstchen模型开发而成,「AIGC开放社区」将根据其论文为大家解读技术原理和功能特性。

与之前的Stable Diffusion系列相比,SC的核心技术思路是将文生图过程拆解成A、B、C三个阶段来完成。
这样做的好处是,在保证质量的前提下可以对图像进行极限分层压缩,然后利用高度压缩的潜在空间实现更优的图像输出,以减少了对传输、算力、存储的需求。
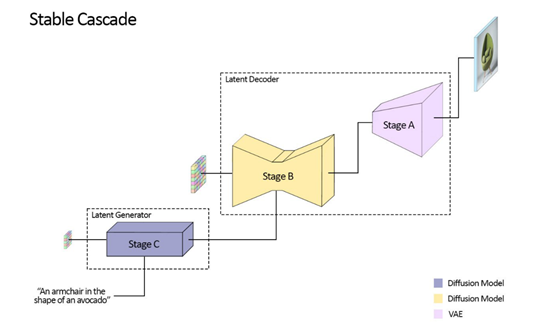
A阶段:潜在图像解码器,通过使用VQGAN模型来解码潜在图像,并生成完整分辨率的输出图像。
VQGAN里面有一个编码器和一个解码器,编码器会把原始图像编码成较低分辨率但信息丰富的离散向量;
解码器则可以从这些向量重构出与原始图像极为相似的图像。整体实现了16倍的数据压缩。
B阶段:以第A阶段的潜在表示为条件,并结合语义压缩器的输出和文本嵌入来进行条件生成。
在扩散过程,重构了第A阶段训练得到的潜在空间,并受到语义压缩器提供的详细语义信息的强烈引导。
这种条件引导,确保了生成的图像可精准还原文本提示,提升对文本的语义理解。
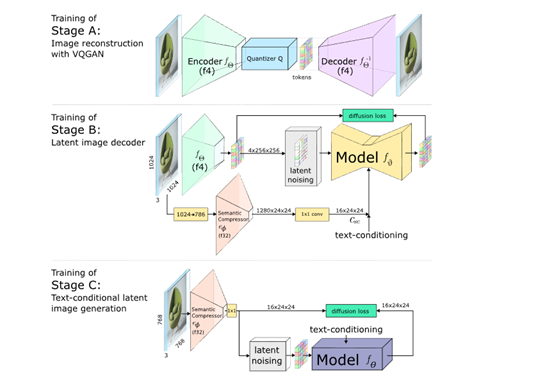
C阶段:以B阶段的生成的潜在图像和输入文本为条件,生成具有更低维度的潜在表示。
通过在低维空间中进行训练和推理,可以更高效地进行扩散模型的训练和生成,大大降低了计算资源的需求和时间成本。
所以,整个图像生成的过程这三大模块就像齿轮一样环环相扣,通过训练一个在低维潜在空间上的扩散模型,并结合高度压缩的潜在表示和文本条件,以及向量量化的生成对抗网络,实现了高效、低消耗的文本到图像合成。
Stable Cascade特色功能
除了文本生成图像之外,Stable Cascade 还可以生成图像变化和图像到图像的特色功能。
图像变化:基于原始图像,在不改变颜色、整体架构的情况下,衍生出更多形态的图像。
其技术原理是,使用 CLIP 从给定图像中提取图像嵌入,然后将其返回到模型中。

图像到图像生成:上传一张图像,然后生成相似形态,不同颜色、类型的图像。其技术原理是,向给定图像添加噪声,然后将其用作生成的起点。

Stable Cascade实验数据
为了测试SC的性能,研究人员将其与SDXL、SDXL Turbo、Playground v2和Würstchen v2主流扩散模型进行了深度比较。
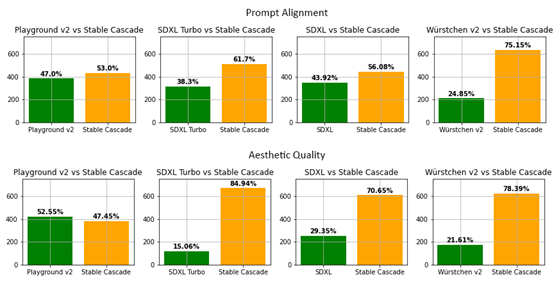
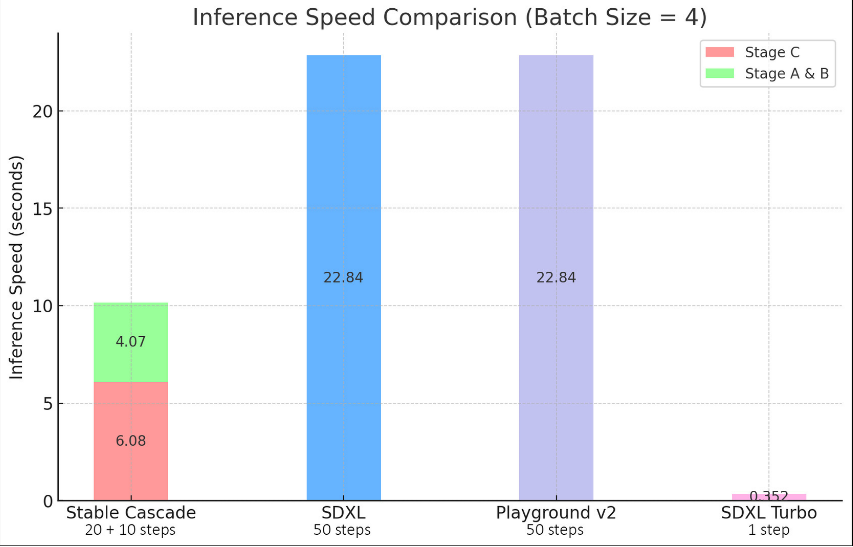
结果显示,Stable Cascade在即时对齐和图像质量方面都表现最佳,推理步骤却比SDXL、Playground v2更少。
此外,在训练Würstchen基础模型时,参数总量比SDXL多14亿,但训练成本仅是其8分之一。
本文素材来源Stability.ai官网、Würstchen论文,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



