让大模型具备自我判断意识,谷歌推出自适应评估框架
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
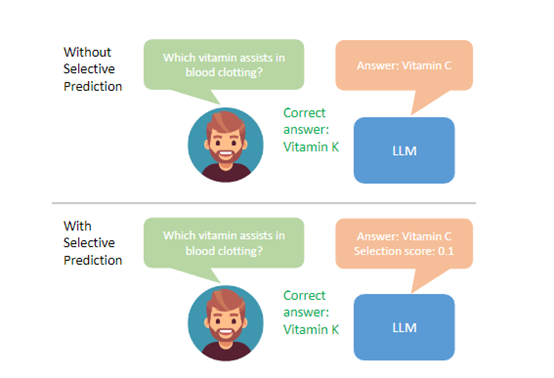
随着GPT-4Turbo、Gemini的神经元越来越多,生成、理解的能力也实现大幅度提升。但在“置信度校准”方面依然很差,经常会生成一些莫名其妙甚至错误的内容。
例如,当用户提出“你知道我今天中午会吃什么菜吗?;你知道我有多少存款吗?”这种无法预测问题时,大模型可能会一本正经的进行解读和猜测。实际上,这是一个根本没有准确答案的模糊问题。
为了提升大模型内容输出的稳定性、准确性和让其具备自我判断意识,谷歌和威斯康星大学的研究人员推出了自适应创新评估框架——ASPIRE。
例如,应用了ASPIRE的大模型,在遭遇上面那种模糊问题时,可以直接了当的回答“抱歉,我不知道。”
论文地址:https://aclanthology.org/2023.findings-emnlp.345.pdf?ref=maginative.com

ASPIRE框架的核心技术思路是基于Self-evaluation(自我评估)的选择性预测、学习逻辑,可以帮助大模型在低置信样本上,进行正确的行为选择。
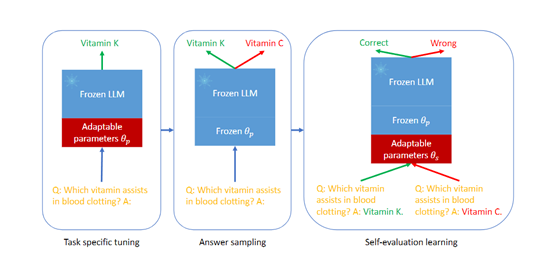
例如,不回答、不进行命名实体识别、情感分析等。主要由任务定向微调、答案采样和自我评估学习三大模块组成。
任务定向微调
通常大语言模型是在大规模预训练数据上进行训练,直接在特定任务上使用可能会导致性能下降。
因此,任务定向微调可以通过使用目标任务的训练数据对大语言模型进行微调,以提高模型在特定任务上的性能。

在微调过程中,模型将在目标任务上进行训练,使其能够更好地理解和生成与该任务相关的文本,使模型能够更好地理解和生成与目标任务相关的文本。
答案采样
答案采样可以生成多个候选答案,并通过评估这些答案的概率分布来估计模型的选择性预测性能。这可以帮助模型评估自己的答案,然后分配一个概率分布。
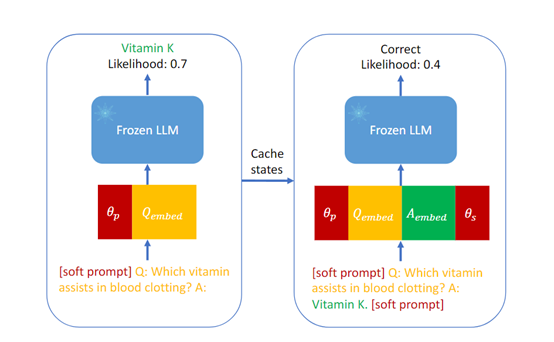
这些概率分布可以用于评估模型对每个答案的置信度。通过答案采样,模型可以更好地判断自己的答案是否可靠,并提供更准确的选择性预测。
自我评估学习
自我评估学习可以让模型通过使用目标任务的训练数据,来学习自我评估的能力,以改进选择性预测性能。
模型会学习将自己生成的答案与目标任务的正确答案进行比较,并生成一个自我评估分数。
这个自我评估分数可以综合考虑模型的答案质量和置信度。在自我评估学习的帮助下,模型可以学会区分正确答案和错误答案,从而提高选择性预测的性能。
实验数据
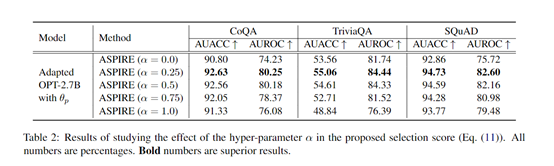
为了测试ASPIRE的性能,研究人员在CoQA、TriviaQA和Natural Questions数据集上进行了测试,ASPIRE皆表现出了高效的性能。
CoQA数据集:ASPIRE框架将答案的准确性提升了。例如,将平均无条件准确率(AUACC)从91.23%提高到92.63%,将平均无条件接收操作特征曲线下面积(AUROC)从74.61%提高到80.25%。这充分表明ASPIRE能够提高大语言模型对答案的选择性预测性能,减少错误答案的生成。
TriviaQA数据集:ASPIRE框架也取得了优秀的成绩,通过将选择性分数阈值设置为0.6,将错误答案的输出减少了35.9%,ASPIRE能够更准确地判断哪些问题的答案不可靠,并避免生成错误答案。
Natural Questions数据集:ASPIRE框架进一步证明了其高效性能,将错误答案的比例降低了11.3%,说明ASPIRE能够在大语言模型的预测中引入更好的选择性,从而提高答案的质量。
本文素材来源ASPIRE论文,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



