面壁智能联合清华开源大模型MiniCPM,魔搭最佳实践来啦!
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
导 读
大模型的一条发展路径是小尺寸的大语言模型,因为尺寸小,有可能以更小的显存运行更强的大模型,并可以和移动端做更好的结合。
最近,面壁智能正式发布了 2B 旗舰端侧大模型面壁 MiniCPM。
MiniCPM是一系列端侧语言大模型,主体语言模型MiniCPM-2B具有2.4B的非词嵌入参数量。在综合性榜单上与Mistral-7B相近(中文、数学、代码能力更优),整体性能超越Llama2-13B、MPT-30B、Falcon-40B等模型。
在当前最接近用户体感的榜单MTBench上,MiniCPM-2B也超越了Llama2-70B-Chat、Vicuna-33B、Mistral-7B-Instruct-v0.1、Zephyr-7B-alpha等众多代表性开源大模型。
同时,面壁智能发布了多模态小模型的MiniCPM-V(OmniLMM-3B),该模型基于MiniCPM-2B和SigLip-400M构建,通过感知器重采样器连接。
多模态小模型带来了更大的想象空间,让我们看到了小型视觉 DIY 机器人项目上运行的实用性,PC端,移动端桌面GUI自动化操作的可行性。
开源地址(内含技术报告)如下:
MiniCPM GitHub:https://github.com/OpenBMB/MiniCPM
OmniLMM GitHub:https://github.com/OpenBMB/OmniLMM
模型链接和下载
MiniCPM系列模型现已在ModelScope魔搭社区开源:
MiniCPM-2B-dpo-fp16:
https://modelscope.cn/models/OpenBMB/MiniCPM-2B-dpo-fp16
MiniCPM-2B-dpo-bf16:
https://modelscope.cn/models/OpenBMB/MiniCPM-2B-dpo-bf16
MiniCPM-2B-dpo-fp32:
https://modelscope.cn/models/OpenBMB/MiniCPM-2B-dpo-fp32
MiniCPM-2B-sft-fp32:
https://modelscope.cn/models/OpenBMB/MiniCPM-2B-sft-fp32
MiniCPM-V:
https://modelscope.cn/models/OpenBMB/MiniCPM-V
OmniLMM-12B:
https://modelscope.cn/models/OpenBMB/OmniLMM-12B
社区支持直接下载模型的repo:
from modelscope import snapshot_downloadmodel_dir = snapshot_download("OpenBMB/MiniCPM-2B-dpo-bf16", revision = "master")
以下为大家带来魔搭社区推理、微调最佳实践教程。
环境配置与安装
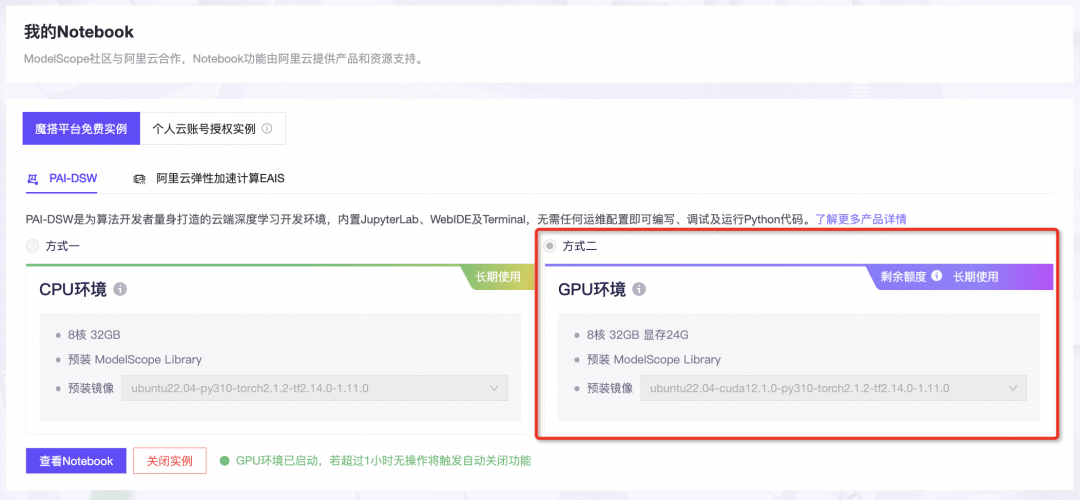
本文使用的模型为 MiniCPM-2B-dpo-bf16 模型,可在ModelScope的Notebook的环境(这里以PAI-DSW为例)的配置下运行(显存24G) 。
环境配置与安装
本文主要演示的模型推理代码可在魔搭社区免费实例PAI-DSW的配置下运行(显存24G) :
点击模型右侧Notebook快速开发按钮,选择GPU环境
模型推理
模型推理
from modelscope import AutoModelForCausalLM, AutoTokenizerimport torchpath = 'OpenBMB/MiniCPM-2B-dpo-bf16'tokenizer = AutoTokenizer.from_pretrained(path)model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, device_map='auto', trust_remote_code=True)dialog = [{'role': 'user', 'content': '请问中国哪几个城市最适合旅游?'}]input = tokenizer.apply_chat_template(dialog, tokenize=False, add_generation_prompt=False)enc = tokenizer(input, return_tensors='pt').to('cuda')output = model.generate(**enc, max_length=1024)print(tokenizer.decode(output[0]))
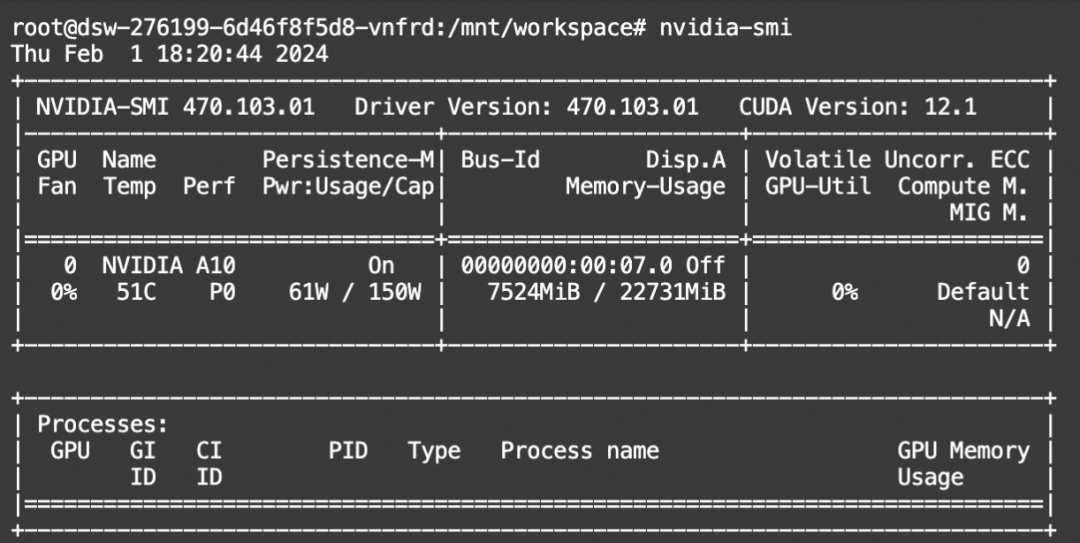
资源消耗:
模型微调和微调后推理
我们使用SWIFT来对模型进行微调, SWIFT是魔搭社区官方提供的LLM&AIGC模型微调推理框架.
微调代码开源地址: https://github.com/modelscope/swift
我们使用数据集jd-sentiment-zh进行微调. 任务是: 对文本进行情感分类.
环境准备:
git clone https://github.com/modelscope/swift.gitcd swiftpip install .[llm]
微调脚本: LoRA
# https://github.com/modelscope/swift/tree/main/examples/pytorch/llm/scripts/openbmb_minicpm_2b_chat# Experimental environment: 2 * A10# 2 * 12GB GPU memorynproc_per_node=2CUDA_VISIBLE_DEVICES=0,1NPROC_PER_NODE=$nproc_per_nodeMASTER_PORT=29500swift sft--model_id_or_path OpenBMB/MiniCPM-2B-sft-fp32--model_revision master--sft_type lora--template_type AUTO--dtype AUTO--output_dir output--ddp_backend nccl--dataset jd-sentiment-zh--train_dataset_sample -1--val_dataset_sample 1000--num_train_epochs 1--max_length 2048--check_dataset_strategy warning--lora_target_modules ALL--gradient_checkpointing true--batch_size 1--weight_decay 0.01--learning_rate 1e-4--gradient_accumulation_steps $(expr 16 / $nproc_per_node)--max_grad_norm 0.5--warmup_ratio 0.03--eval_steps 100--save_steps 100--save_only_model true--save_total_limit 2--logging_steps 10--use_flash_attn false
训练过程支持本地数据集,需要指定如下参数:
--custom_train_dataset_path xxx.jsonl--custom_val_dataset_path yyy.jsonl
自定义数据集的格式可以参考:
https://github.com/modelscope/swift/blob/main/docs/source/LLM/自定义与拓展.md
微调后推理脚本:
(这里的ckpt_dir需要修改为训练生成的checkpoint文件夹)
# Experimental environment: A10CUDA_VISIBLE_DEVICES=0swift infer--ckpt_dir "output/openbmb-minicpm-2b-sft-chat/vx_xxx/checkpoint-xxx"--load_dataset_config true--max_length 2048--use_flash_attn false--max_new_tokens 2048--do_sample false
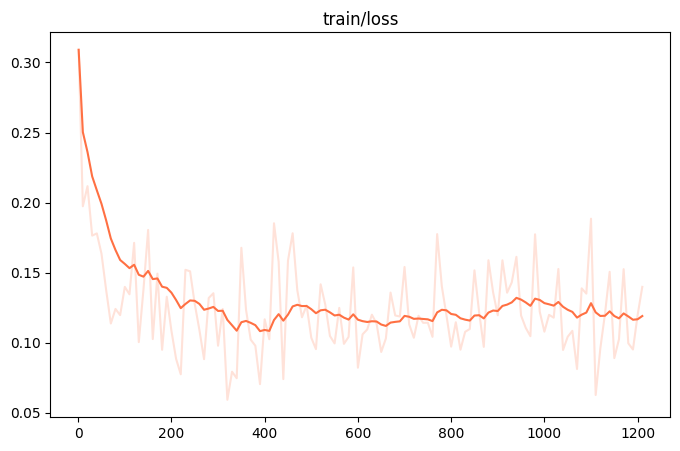
训练loss图:
训练后生成样例:
[PROMPT]<s> <用户>Task: Sentiment ClassificationSentence: 口感相当的好 都想买第二次了Category: negative, positiveOutput:<AI>[OUTPUT]positive</s>[LABELS]positive--------------------------------------------------[PROMPT]<s> <用户>Task: Sentiment ClassificationSentence: 质量不错,大小合适,应当是正品!但是我买的是黑灰,发来的却是纯黑,懒得换了,给个差评,希望以后改进!Category: negative, positiveOutput:<AI>[OUTPUT]negative</s>[LABELS]negative--------------------------------------------------[PROMPT]<s> <用户>Task: Sentiment ClassificationSentence: 一般吧,冰糖太多了Category: negative, positiveOutput:<AI>[OUTPUT]negative</s>[LABELS]negative--------------------------------------------------
本文素材来源 魔搭ModelScope社区,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



