字节跳动推出超高清文生视频模型,效果比Gen-2更强!
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
字节跳动的研究人员开发了一种超高清文生视频模型MagicVideo-V2。
MagicVideo-V2公布的实验评测数据显示,视频的高清度、润滑度、连贯性、文本语义还原等方面,比目前主流的文生视频模型Gen-2、Stable Video Diffusion、Pika 1.0等更出色。
这是因为,MagicVideo-V2将文生图像、图像生成视频、视频到视频和视频帧插值4种功能整合到一个模型中,解决了之前面临的4大难题。
论文地址:https://arxiv.org/abs/2401.04468
项目地址:https://magicvideov2.github.io/
一只穿着紫色长袍的胖兔子,走过一片魔幻的风景(由MagicVideo-V2生成)

随着Gen-2等模型的出现,文生视频领域实现飞速发展,尤其是在这个短视频时代被大量用户应用。但是在生成的过程中,模型经常面临4个难题。
一个女巫正在制作药品
视频不美观,由于多数是采用公开训练数据,生成的视频经常会出现劣质的情况;内容不一致,在生成视频的过程中,无法精准还原文本提示的内容;
视觉质量和清晰度较差:如何将用户的文本提示,转化为高清、精准高质量视频很难;
视频运动不连贯,多数模型无法在生成的关键帧之间,插入额外的帧,使视频的运动更加自然和连贯性。
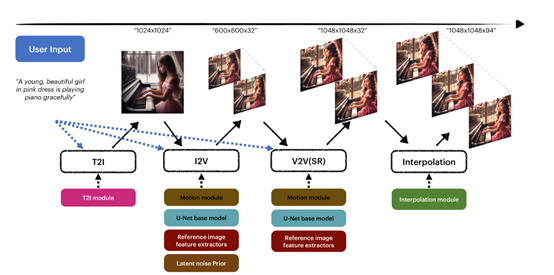
所以,字节跳动的研究人员直接将4个模块整合在MagicVideo-V2模型中,一一解决了这些难题。
文生图像
文生图像模块(Text-to-Image, T2I)主要用于接收用户提供的文本描述作为输入,并生成一个1024×1024像素的图像作为视频生成的参考图像。这有助于增强视频的内容和美学风格。

T2I模型采用基于扩散的生成模型,通过多个迭代步骤逐渐生成高质量的图像,同时可以学习到从文本描述到图像的映射关系,从而生成与文本描述相符的精美图像。
图像到视频
该模块基于SD1.5模型,通过人类反馈来提高模型在视觉质量和内容一致性方面的能力。图像到视频模块还使用了一个参考图像嵌入模块,用于利用参考图像。
具体来说,研究人员使用了一种外观编码器来提取参考图像的嵌入,并通过交叉注意机制将其注入到图像到视频模块中。
一只熊猫趴在冲浪板上,夕阳,4K超清
这样,图像提示可以有效地与文本提示解耦,并提供更强的图像条件。此外,使用了潜在噪声先验策略,通过在起始噪声潜变量中引入适当的噪声先验技巧,保留部分图像布局,改善帧之间的时间连贯性。
视频到视频
该模块进一步对低分辨率视频的关键帧进行优化和超分辨率处理,以生成高分辨率的视频。
简单来说,就像照相机的美颜功能,会根据图像内容自动生成更丰富的像素级细节,增强整体逼真度与纹理细节。
钢铁侠在燃烧的城市人上飞行,细节逼真,4K超高效果
这也是比其他文生视频模型更高清的重要原因之一。
视频帧插值
该模块可以在生成的视频关键帧之间插入额外的帧,增加视频的平滑性、动态感以及连贯性。
主要通过分析相邻关键帧之间的运动信息,以及参考图像和文本描述,插入中间帧,使视频的运动更加连续和自然。
测试数据
为了评估 MagicVideo-V2的性能,研究人员使用了人类评估和目前最先进的 T2V 系统两种评估方法。
分别由61位评估者组成的小组对 MagicVideo-V2 和另一种 T2V 方法进行了 500 次并排比较。
在每一轮比较中,每位投票者都会看到一对随机的视频,包括基于相同文本提示的一个我们的视频和一个竞争对手的视频。他们会看到三个评估选项–“好”、”一样 “或 “坏”–分别表示偏好 MagicVideo-V2、无偏好或偏好竞争的 T2V 方法。
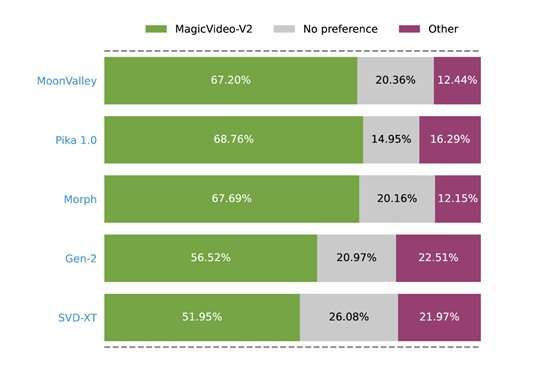
投票者需要根据他们对三个标准的总体偏好进行投票:1) 哪种视频具有更高的帧质量和整体视觉吸引力。2) 哪种视频的时间一致性更高,运动范围和运动连贯性性更好。
3) 哪个视频的结构错误或不良情况更少。测试结果表明,MagicVideo-V2 明显更受评估者青睐。
本文素材来源MagicVideo-V2论文,如有侵权请联系删除
END

本篇文章来源于微信公众号: AIGC开放社区



