700亿参数,可商用!Meta开源3个最强代码大模型
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
全球科技巨头Meta在社交平台开源了,3个专业代码大语言模型Code Llama 70B、CodeLlama-70B-Python和CodeLlama-70B-Instruct。
据悉,这三款模型都是基于Meta的Llama 2开发而成, 比去年发布的三款70亿、130亿、340亿三款专业代码模型参数更大,这也是截至目前参数最大、功能最强的纯代码模型之一。
就连Meta联合创始人扎克伯格都为Code Llama 70B代码模型站台官宣,可见其性能以及Meta对其重视程度。
Github地址:https://github.com/facebookresearch/codellama?ref=maginative.com
模型权重下载地址:https://ai.meta.com/resources/models-and-libraries/llama-downloads/
由于Meta暂时没有公布Code Llama 70B的论文,「AIGC开放社区」就用Meta曾经发布的Code Llama论文为大家介绍下。
论文下载地址:https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/
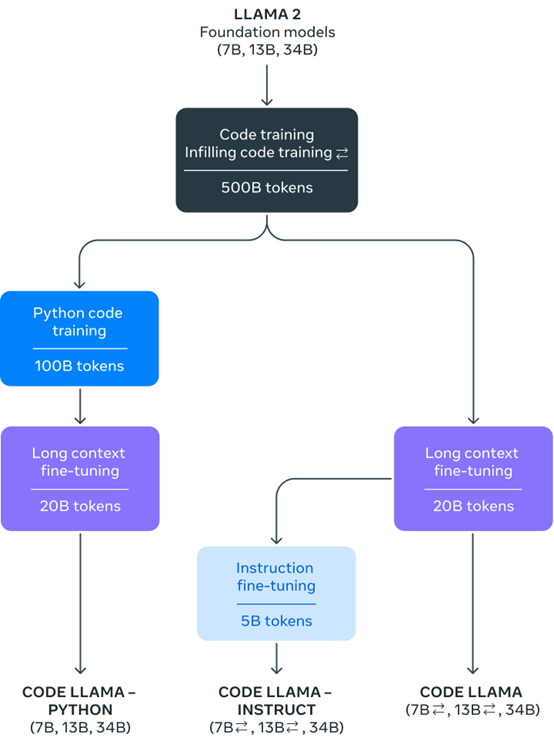
Code Llama是基于目前最强开源大语言模型Llama 2开发而成,在代码和文本数据上进行预训练、微调,提升代码生成和理解能力。
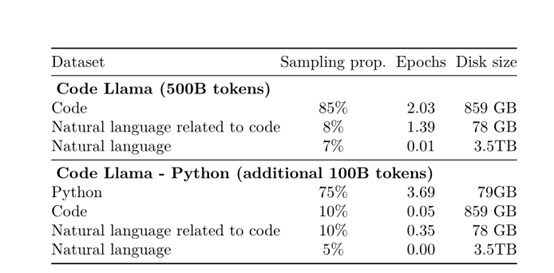
目前,一共有70亿、130亿、340亿和700亿四种参数。除了基础模型之外,还有Python和Instruct两种特殊微调模型,每个模型都使用了5000亿tokens优质代码数据进行训练。
其中,70亿和130亿的 Code Llama模型采用了多任务目标,包括自回归和因果填充预测方法。为了提升输入扩展,研究人员进行了额外的微调步骤,将上下文长度从4,096tokens扩展到了100,000tokens。
Python是目前代码生成方面最高效、应用最广的编程语言之一,并且Python 和 PyTorch 在AI 社区中发挥着重要作用。
所以,Meta推出了针对Python的代码模型。该模型在 1000亿标记的优质Python代码进行微调。
Code Llama – Instruct 则是 Code Llama 针对自然文本指令微调的模型,该模型支持自然文本输入和输出。
如果你想使用文本生成代码,Meta建议使用该模型,因为Code Llama – Instruct已经过数据微调理解自然文本更好并且生成的代码更符合开发人员要求。
资源消耗方面,70亿参数模型可在单个GPU上运行。340亿参数模型可返回最佳结果并提供更好的编程辅助,但资源消耗更大。所以,本次发布的700亿参数模型,在AI算力方面也比前三个消耗更多。

根据Meta公布的消息,Code Llama 70B 在 HumanEval 基准测试中的准确率达到 53%,比 GPT-3.5 的 48.1% 表现更好,更接近OpenAI的GPT-4 67%,是目前性能最强的开源代码模型之一。
此外,Code Llama 70B的多语言支持、子任务执行、内容安全方面,也是同类开源模型中最佳之一。
本文素材来源Code Llama论文,如有侵权请联系删除
END


本篇文章来源于微信公众号: AIGC开放社区



