麻省布里格姆医院:ChatGPT在临床决策中,准确率高达71.7%!
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
美国最大非营利医疗机构之一麻省布里格姆医院发布了,关于ChatGPT在临床医疗决策中应用的研究论文。
该医院表示,从提出诊断、推荐诊断检查到最终诊断以及护理管理决策,ChatGPT的准确率为71.7%,在整个临床决策中的表现令人感到惊讶。
特别是与初始诊断相比,ChatGPT 在最终诊断任务中表现出了最高的准确率76.9%。
此外,ChatGPT在所有医学专业的初级保健和急诊环境中表现同样出色,可以充当医疗助手角色辅助主治医生增强决策、治疗和护理等医疗工作,在医疗领域的应用潜力巨大。
论文地址:https://www.jmir.org/2023/1/e48659/
评估方法
研究人员评估了ChatGPT 在解决医疗综合临床决策方面的准确性,比较了患者的年龄、性别和临床表现的敏锐度。
通过将临床工作流程的每一部分,作为对模型的连续提问,依次提出鉴别诊断、诊断测试、最终诊断和临床管理。

数据来源和测试
测试数据选自《默克手册》,这世界上最古老和最广泛使用的医学参考书之一,涵盖了各种疾病和医疗状况的详细信息,包括症状、病因、诊断、治疗和预防等内容。
例如,现病史 (HPI)、系统审查 (ROS)、体检(PE) 和实验室测试结果等,以模拟鉴别诊断、诊断检查和临床管理中的决策。
病例记录是通过将《默克手册》插图直接复制到 ChatGPT 中生成的。所有要求临床医生分析图像的问题都被排除在研究之外,因为ChatGPT 还无法准确识别医疗图片信息。
评分方法,ChatGPT每回答对一道题将获得1分,例如,每次 ChatGPT 的答案与提供的《默克手册》答案一致时都会获得一分。每一道题的最终分数计算为 3 次重复分数的平均值。
不同患者和年龄的表现
研究人员进行了多变量线性回归分析,以研究患者年龄和性别对ChatGPT 准确性的影响。年龄和性别的回归系数均不显着(年龄:P= .35;性别:P = .59;)。
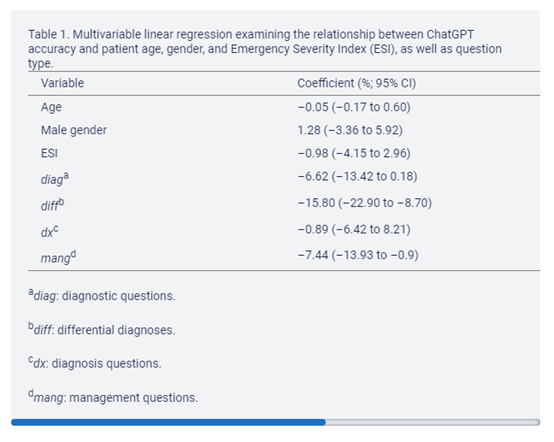
这一结果表明,ChatGPT的表现在本研究中的各个年龄段,以及性别的二元定义中都是相同的。
测试结果
ChatGPT在所有36个临床测试题中的总体准确率达到71.7%;
在做出最终诊断方面表现出最高的表现,准确率为76.9% ;
在生成初级鉴别诊断方面表现最低,准确率为60.3%。
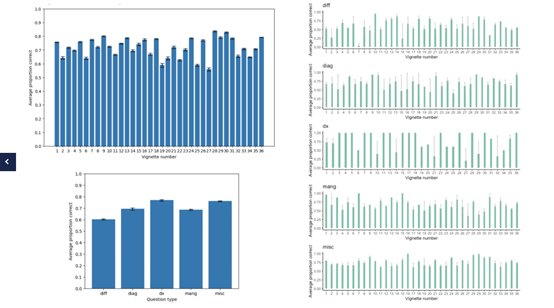
总体来说,ChatGPT在临床决策方面取得了令人印象深刻的准确性,并且随着它获得更多可用的临床信息将变得越来越强大。特别是,与初始诊断相比,ChatGPT在最终诊断任务中表现出最高的准确性。
在用药方面,ChatGPT可以提供正确用药但无法给出准确的剂量,这可能表明ChatGPT的训练数据偏向于语言准确性,而不是数字准确性。
如果想获得更准确的答案,可能需要对模型进行特定领域的数据训练和微调。
关于麻省布里格姆医院
麻省布里格姆医院由麻省总医院(Massachusetts General Hospital)和布莱根妇女医院(Brigham and Women’s Hospital)于1994年合并而成。
麻省总医院,全名马萨诸塞州公共卫生和总医院,是美国最古老和最有声望的医疗机构之一,创立于1811年总部位于波士顿。麻省总医院是美国排名第一的研究型医院,同时也是哈佛医学院的主要教学医院。
在过去的200多年中,麻省总医院一直在医疗创新和研究领域处于领先地位。例如,1846年,进行了世界上第一次成功的全麻手术。此外,该医院在医学影像、心脏病学、神经科学和许多其他领域做出了重要贡献。
本文素材来源麻省布里格姆医院官网,如有侵权请联系删除
END

本篇文章来源于微信公众号: AIGC开放社区



