创新性文生视频模型,南洋理工开源FreeInit
添加书签

专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
文本领域的ChatGPT,画图领域的Midjourney都展现出了大模型强大的一面,虽然视频领域有Gen-2这样的领导者,但现有的视频扩散模型在生成的效果中仍然存在时间一致性不足和不自然的动态效果。
南洋理工大学S实验室的研究人员发现,扩散模型训练和推理阶段初始噪声的频率分布不均匀,是导致生成视频质量下降的重要原因之一。因此,开发了创新性文生视频模型FreeInit。
FreeInit的核心技术概念是通过重新初始化噪声,来弥合训练和推理之间的差距。研究人员提出了一种创新性的推理采样策略,通过迭代地改进初始噪声的空时低频分量,从而提高时间的一致性。
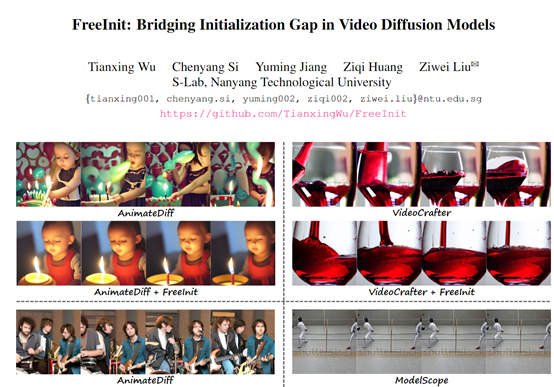
为验证FreeInit的有效性,研究人员在多个文到视频生成模型上进行了大量实验,包括AnimateDiff、ModelScope和VideoCrafter等。结果显示,FreeInit可以使这些模型的时间一致性指标提高2.92—8.62。
开源地址:https://github.com/tianxingwu/freeinit
论文地址:https://arxiv.org/abs/2312.07537v1
为了找出文生视频模型效果不佳的原因,研究人员通过对多个模型的信噪比进行检测,惊奇地发现,视频扩散模型的推理初始化噪声中,低频信息很难被完全移除。
这与高斯白噪声初始化存在明显的分布差距。这种低频信息残留,可能就是导致生成视频效果的时间线,不连贯的主要原因。
为了验证这个想法,研究人员设计了一个创造性的测试实验:他们收集真实视频,使其经过扩散模型的正向推理,得到具有强相关性的噪声;然后再用这个噪声作为推理的初始化,继续生成视频。
结果发现,与高斯噪声相比,相关噪声生成的视频时间一致性和细节清晰度明显增强。这充分证明了低频信息对推理质量的关键影响,也证实了训练推理初始化的差距确实是重要原因。

而FreeInit的创新点在于,在模型推理的过程中可精炼低频信息,逐步弥合训练推理的差距,使初始化噪声分布逼近相关性更强的训练噪声,从而生成时间一致性更好的视频。
采样、扩散模块
FreeInit在推理的第一步,先初始化独立高斯噪声,然后通过经典的DDIM离散采样策略,采样生成初步的视频潜码。
通过利用扩散模型已有的去噪功能,从完全随机的噪声中采样出较为清晰的视频潜码。
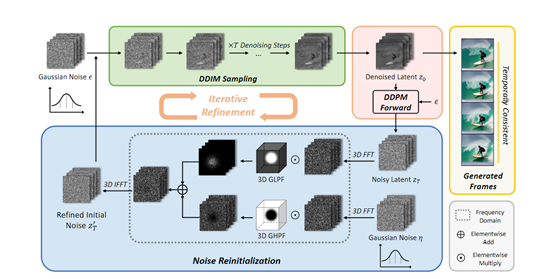
接着获取上一步生成视频潜码的带有时间相关性的噪声版本,将生成的视频潜码通过原始的高斯噪声进行正向扩散过程,使其重新含有低频时间相关信息。
这里需要复用DDIM采样中使用的高斯噪声,避免引入过多额外随机性。最终得到低频信息较丰富的噪声潜码。
噪声重新初始化
将得到的含低频相关性噪声与新的高斯噪声高频部分结合,得到重新初始化的噪声,并为下一轮采样的初始提供输入。
这里采用频域分解的方式:先通过3D FFT变换噪声潜码到频域,然后与新的高斯噪声通过低通滤波器和高通滤波器分别提取低频和高频部分后拼接。该模块在保留低频信息的同时,也为高频部分引入额外灵活性。

将上述多个模块进行联合、重组,便形成了一次完整的采样优化过程。研究者表示,进行多次重复迭代,可以进一步累积提升低频信息质量,逐步弥合训练和推理的初始化差距,最终让生成视频质量不断改善,时间一致性也越来越好。
本文素材来源FreeInit论文,如有侵权请联系删除
END

本篇文章来源于微信公众号: AIGC开放社区



