性能优于GPT4-V,华为、港大开源几何数学模型G-LLaVA
添加书签
专注AIGC领域的专业社区,关注微软&OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
大型语言模型在内容生成、逻辑推理等方面展示了强大的能力,但在处理专业几何数学难题时效果不佳。
这是因为,与文本数学题相比,几何空间数学题对模型的视觉理解和逻辑思维能力更高要求。目前,多模态大语言模型仍无法准确解析几何图形中的基本要素及其关系。
为了解决这一难题,华为诺亚方舟实验室、香港大学、香港科技大学联合开源了专业几何数学模型G-LLaVA。
为了测试G-LLaVA的性能,研究人员在知名数学测试平台 MathVista上,与其他大模型进行了深度评估。结果显示,G-LLaVA的性能超过了GPT-4-V、LLaVA1.5、MiniGPT-4等模型。
开源地址:https://github.com/pipilurj/G-LLaVA
论文地址:https://arxiv.org/abs/2312.11370

整体架构
G-LLaVA的整体架构主要包含大语言模型、图像编码器和投影层三大模块。
1)大语言模型使用的是LlAMA模型,用于理解和生成文字序列。相比通用模型,G-LLaVA的语言模型通过几何数据获得了数学和视觉领域的适配。
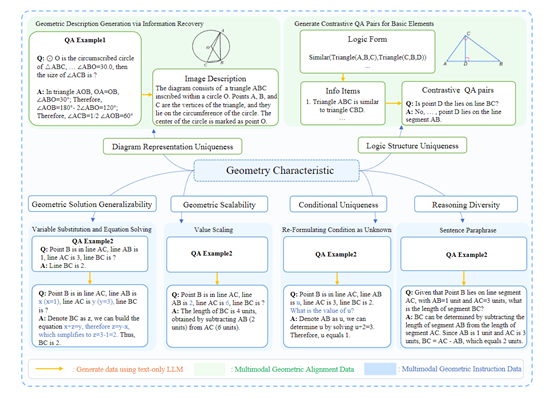
2)图像编码器利用预训练的视觉ViT等,进行特征提取和图像理解,可将输入的几何图像和问题转化为向量表示并生成答案。
3)投影层是一个线性层,作用是将图像编码器输出的视觉特征投影和映射到语言模型的嵌入空间中。这实现了不同模态特征的对齐融合,让大语言模型可以识别几何图像的关键所在。
训练方法
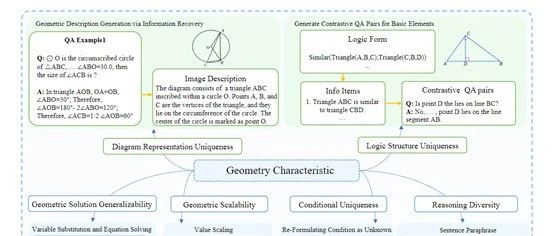
G-LLaVA使用的是双阶段渐进式训练方法:几何视觉语言对齐,这一阶段专注于增强模型对几何图像的理解,令其准确解释几何图形基本要素。
构建的对齐数据集包含图像描述和判断对比问答。只优化投影层参数进行对齐训练。

几何指令调优,在调整阶段,利用变量建模、数据增强等策略生成大规模几何问题解答数据。通过解题过程的复现,提高G-LLaVA的数学建模建、关系、符号推理的能力。调优后的模型可接收几何图像和自然文本提示并输出内容。
构建Geo170K数据集
G-LLaVA能具备强大的几何理解能力,这个Geo170K数据集是关键。
Geo170K的数据来源包括多个已有的开源几何QA数据集,例如,Geometry3K、GeoQA和GeoQA+。
这些数据集提供了丰富的几何图像样例和部分注释, Geo170K的总规模超过17万条。
包含约6万张几何图像及匹配描述,和11万多个问题-解答语言配对。这远超过此前最大的图形问答集GeoQA+。数据分布覆盖了基本几何要素的判定、定量关系的符号推理等多个方面。
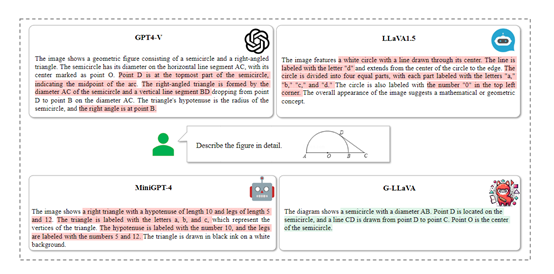
为了评估G-LLaVA的性能,研究人员在MathVista等测试平台进行了一系列实验,与其他现有的知名大语言模型进行了比较。
实验结果显示,G-LLaVA与GPT-4-V和其他MLLMs相比,G-LLaVA的性能超过了GPT-4-V、LLaVA1.5、MiniGPT-4等模型。显著提高了几何难题的解决准确率和效率。
这表明通过引入对齐的多模态数据集,可以有效地提升大语言模型在处理几何问题时的能力。
此外,研究人员还对G-LLaVA模型进行了进一步的分析,以探索其在各个几何问题类型上的性能差异。
实验结果显示,G-LLaVA模型在处理点、线、角等基本几何元素的问题时表现仍然出色。
本文素材来源G-LLaVA论文,如有侵权请联系删除
END

本篇文章来源于微信公众号: AIGC开放社区



