专注AIGC领域的专业社区,关注微软OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
随着ChatGPT等大模型被广泛应用在实际业务中,其输出内容的真实、可靠、安全性成为了重点。学术界则使用“归因”来表示追查、证实内容。
目前,在“归因”研究领域有两大派系,一种是协同归因,主要追查引用数据和训练数据来源;另外一种是贡献归因,证明模型输出内容的真实性以减少幻觉。
这两种归因方法对于法律、医疗、金融等,对于内容准确率要求极高的行业应用大模型至关重要。
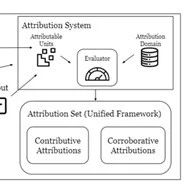
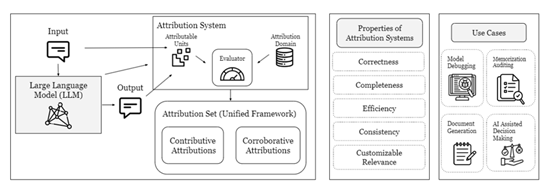
但是这两种研究方法是分开独立进行的,所以,斯坦福大学的研究人员提出了“统一归因”框架,将两种方法集成在一起。
论文地址:https://arxiv.org/abs/2311.12233
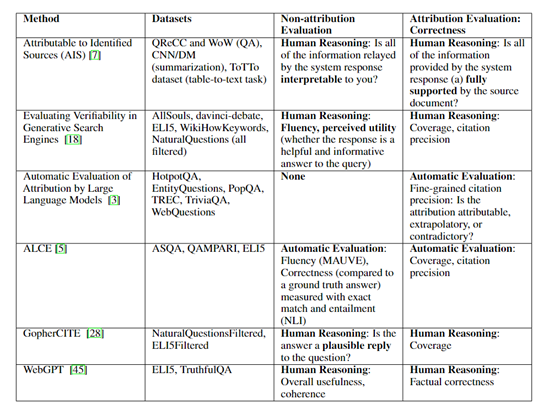
协同归因主要是用来验证大模型的输出是否正确,并与外部的知识进行比较。例如,我们可以通过生成一些相关的引文或参考文献来追溯大模型输出的来源,并验证它的准确性。
同时可以通过从外部的知识库中检索相关的知识,然后与大模型的输出进行对比和验证。具体功能如下:
引文生成验证:该功能是生成与大模型输出相关的引文或参考文献。它会在知识库或文献数据库中搜索相关的文献,并根据大模型输出的内容生成相应的引文,以追溯大模型输出的来源,并验证其准确性。
例如,通过自然语言处理技术和信息检索技术,验证关键词匹配、文本摘要生成等。
知识检索验证:该功能是从外部的知识库中检索与大模型输出相关的知识,可以利用知识图谱、在线百科全书或专业数据库等资源,通过关键词匹配或语义相似度计算来检索相关的知识。
然后,将检索到的知识与大模型的输出进行对比和验证,以确定其准确性和一致性。
事实验证:可以通过对外部数据源或可信的事实数据库进行查询来实现,通常利用自然语言处理技术和数据匹配算法,将大模型的输出与事实进行比对,从而判断其准确性和可信度。
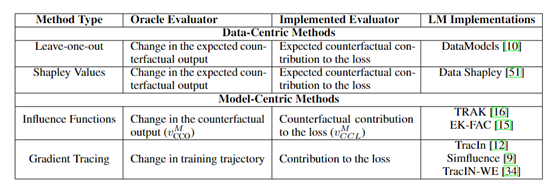
贡献归因方法主要是用来确定训练数据对大模型输出的影响有多大。例如,我们可以对训练数据进行微小的变动,然后观察大模型输出的变化,从而计算出每个训练样本对大模型输出的影响程度。
另外,可以生成一些模拟的数据,并比较它们与真实数据集上大模型输出的差异,这样就可以推断出训练数据的贡献程度。具体功能如下:
影响函数验证:通过对训练数据进行微小的变动,观察大模型输出的变化来实现。
开发者可以设计一些影响函数来度量变动对大模型输出的影响程度,就可以确定哪些训练数据对大模型输出具有重要影响,从而更好地理解模型的行为。
数据模拟器验证:通过生成一些与真实数据相似但有差异的数据,可以观察大模型输出的差异,从而推断出真实数据对大模型输出的贡献程度。
数据模拟器验证可以利用生成对抗网络(GAN)或其他生成模型来生成模拟数据。
数据模型验证:通过构建一个数据模型,用于表示大模型对训练数据的学习和预测过程。数据模型可以是一个统计模型或神经网络模型。
通过分析数据模型,开发者们可以确定哪些训练数据对大模型输出具有重要性,并对模型的训练和优化过程进行解释。
斯坦福便是将协同归因和贡献归因的主要功能,整合在一个框架中方便开发者对大模型进行各种安全、内容验证。
本文素材来源斯坦福论文,如有侵权请联系删除
END

本篇文章来源于微信公众号: AIGC开放社区