OpenAI公布ChatGPT安全框架:跟踪、评估、安全基线等
添加书签

专注AIGC领域的专业社区,关注微软OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
12月19日,OpenAI在官网公布了“准备框架”(Preparedness Framework)测试版。该文档详细介绍了OpenAI是如何保证ChatGPT等产品的安全防护措施、开发和部署流程。
OpenAI表示,随着大模型的功能迭代不断完善,其能力已经开始接近初级AGI(通用人工智能),安全已成为开发AI模型的重中之重。
因此,OpenAI希望通过详细公布AI模型的安全框架透明化,使社会、用户深度了解模型的工作机制,确保以安全、健康的方式应用在实际业务中。同时为研发超级模型奠定安全基础。
详细文件地址:https://cdn.openai.com/openai-preparedness-framework-beta.pdf

跟踪风险类别
OpenAI明确列出了4类可能带来灾难性后果的风险领域需要特别关注,分别是网络安全风险、CBRN风险(化学、生物、放射性、核)、说客能力风险以及模型的自主能力风险。
并对每一类风险安全框架都给出了低、中、高、特别高四个等级,来描述系统在该风险领域所处的危险水平。

以网络安全风险为例,框架将低级定为系统仅可以用于非编程任务;中级为系统可以明显提高黑客攻击效率;高级为系统能够自动发现和利用高价值漏洞;
特别高级为系统能够自动找到和利用任何软件的漏洞。这种细分的安全体系,可以指导开发人员更精准的评估模型。
建立安全基线
OpenAI设定了严格的安全基线:只有在减轻后评分,为”中等”或以下的模型才能部署;只有安全评分为”高”的模型才能进一步开发、应用。
此外,对于评分卡中具有”高”或”关键”风险的模型,OpenAI还将确保相应的安全措施,以防止模型被窃取。
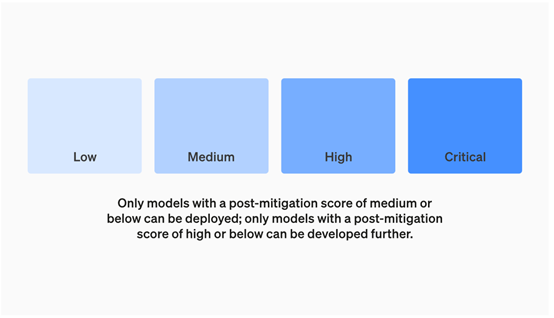
同时会定期动态跟踪和更新各类风险的“加强前”和“加强后”评级情况。“加强前”评估系统本身的风险水平,“加强后”看系统采取了哪些安全预防措施后余下的风险。
例如,某次评估显示,在没有采取任何措施的情况下,一个新模型在网络安全方面的加强前风险达到了高级。
经过一轮实验验证后,通过设计专门的安全模组后,该模型的加强后风险降到了中等水平。这可以清晰地告诉研发人员模型当前的安全状况,以及应采取哪些补救措施。
建立安全咨询团队
OpenAI将成立一个名为”安全咨询小组”(Safety Advisory Group,SAG)的跨职能咨询机构。该小组将汇集公司内部的专业知识,帮助OpenAI的领导层和董事会做出最佳的安全决策。
安全咨询小组的职责包括监督风险评估工作、维护应急情况处理的快速流程等。
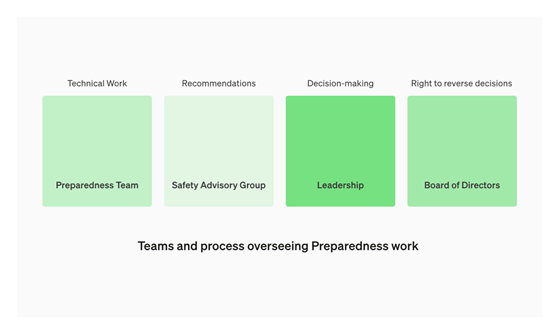
OpenAI还成立了一个“准备团队”,专门负责模型的安全研发和维护。该团队将进行研究、评估、监测和预测风险,并定期向”安全咨询小组”提供报告。
这些报告将总结最新的安全证据,并提出改进OpenAI研发大模型的安全计划建议。
此外,准备团队还将与相关团队(如安全系统、安全性、超级对齐、政策研究等)协调合作,整合出有效的安全措施。
此外,准备团队还将负责组织安全演练,并与可信AI团队合作进行第三方安全审计。

需要注意的是,这是一份动态文档,OpenAI会根据实际的安全情况对内容进行更新和说明。
本文素材来源OpenAI官网、Preparedness Framework文档,如有侵权请联系删除
END

本篇文章来源于微信公众号: AIGC开放社区



