专注AIGC领域的专业社区,关注微软OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
在许多3D场景捕获中,由于网格重建失败或者缺乏观测,例如,物体接触区域或难以触及的区域,场景中的某些部分经常会出现缺失的情况。
谷歌和加州大学伯克利分校的研究人员提出了NeRFiller框架,可通过2D图像来修复残缺的3D场景,同时发现当图像形成2×2网格时,会生成更多3D一致性的修复效果。
测试数据显示,研究人员通过多个评估指标对比原始数据与重建效果,如PSNR、SSIM等。同时记录不同数据集每个迭代循环耗时,发现NeRFiller重建的效果更出色,并将重建效率提升了10倍左右。
即将开源地址:https://github.com/ethanweber/nerfiller
论文:https://arxiv.org/abs/2312.04560
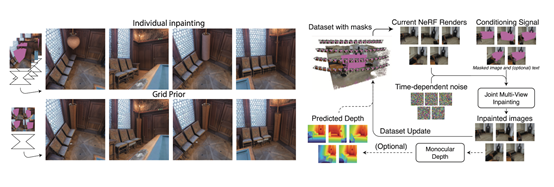
通常3D修复目标是完成一个包含缺失区域场景,例如,由多视图重建方法获得的场景,其中可能存在由于网格重建失败导致的“空洞”。NeRFiller则是要填充这些缺失区域,生成一个完整的3D场景。
所以,NeRFiller的整体修复思路主要分为两大块:使用联合多视角图像补全一致性的3D模型,以及通过对3D场景表示的迭代优化,将这些2D图像补全整合到全局一致的3D场景中。
使用独立的2D补全模型进行多视角图像的补全存在一致性问题,因此NeRFiller提出了网格先验和联合多视角补全两种策略,来提高一致性。
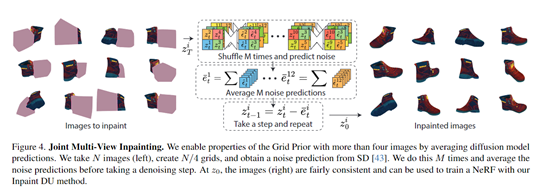
研究人员发现,将四幅图像缩放到较低分辨率后以2×2网格形状提供给补全模型,可以获得更加一致的补全结果。可能这是由于在补全模型的训练数据中,存在很多视图示例。
方法是将4幅图像的潜在表示缩放到1/4分辨率,拼接成2×2网格后提供给扩散模型,对网格进行联合预测和采样。
最后再还原到原分辨率。这与最近的视频编辑方法使用的延长注意力机制有相似之处。
直接将大量图像制作成网格会降低分辨率。为了保持分辨率,NeRFiller使用了一种将网格先验推广到任意数量图像的策略。
该策略类似于MultiDiffusion的方法,每次迭代时随机将图像分组到2×2网格中,重复多次后对每个图像的噪声预测进行平均。这样可以在不降低分辨率的情况下增加有效的网格大小。
上述的联合多视角图像补全,还无法更好的保证3D场景一致性。所以,NeRFiller使用了一种将2D补全结果整合到3D场景表示的迭代方法。整体流程如下:
-
渲染训练视角子集;
-
对渲染图像添加噪声,进行联合多视角补全;
-
用补全结果更新训练数据集中对应图像。
不断重复该流程,直到重建结果达到目标。此外,为了优化3D场景的几何形态,NeRFiller在室内场景中可加入了相对深度的监督,补全后预测深度,只对补全区域施加排序损失。
本文素材来源NeRFiller论文,如有侵权请联系删除
END

本篇文章来源于微信公众号: AIGC开放社区