高性能多模态大模型,华中科技大学开源Monkey
添加书签
专注AIGC领域的专业社区,关注微软OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
目前,很多多模态大模型在理解和处理复杂的场景,以及细微的视觉细节时仍面临很大挑战,主要是受限于输入分辨率(如448 x 448)以及训练集图像和文本描述之间的不匹配。
为了解决这些难题,华中科技大学与金山软件联合推出了Monkey框架并将其开源。Monkey无需从0预训练,可以基于现有视觉编辑器(如Vit-BigHuge)进行构建,将大模型的输入分辨率能力提高到896 x 1344像素。
此外,Monkey还提出了一种多级描述生成方法,该方法自动提供丰富的信息,可以指导模型学习场景和对象之间的上下文关联。
为验证Monkey的性能,研究人员在16个不同的数据集上进行了丰富测试,涵盖图像字幕、视觉问答、文档分类以及图像理解等多模态任务,Monkey皆取得了出色的成绩。
开源地址:https://github.com/Yuliang-Liu/Monkey
论文地址:https://arxiv.org/abs/2311.06607v1

训练数据与模型
高质量训练数据集是提升大模型能力的关键点之一,所以,研究人员生成了数十万条高质量的图像描述数据,并通过多级方法捕捉图像的全貌和局部细节。
还利用BLIP2、PPOCR、GRIT、SAM等模型自动生成文字描述,然后把不同模型输出的内容融合起来,组成清晰和连贯的图文匹配数据。这种数据生成方法,显著提升了大模型图像细节的理解能力。

模型选择方面,直接应用了开源模型Qwen-VL作为语言解码器,并使用了20亿参数的ViT-BigHuge作为视觉编码器。这可以极大提高了研发的效率,避免重复预训练耗费资源。
训练方法
为了提升Monkey多模态大模型的识别能力、输入分辨率,生成更丰富的图像描述以及对复杂场景的理解能力,采用了三个训练阶段:
(1)多级描述生成:该模块主要通过BLIP2、GRIT、PPOCR等多个模型的协同,为图像自动生成包含全局特征和局部细节的语义描述。
(2)高分辨率编码:采用滑动窗口分割高分辨率图像,并行使用多个视觉编码器对各个局部区域进行编码,同时保留全局图像的结构信息。例如,一张2048像素的高清图片,Monkey会将其均分成16块。

(3)多任务训练:使用包含图像字幕、视觉问答等多种任务的数据集进行联合训练,提升模型的泛化能力。指令格式统一为:Generate/Answer + 问题/命令,并限制每个任务使用的数据量,有助于保证训练平衡。
实验数据
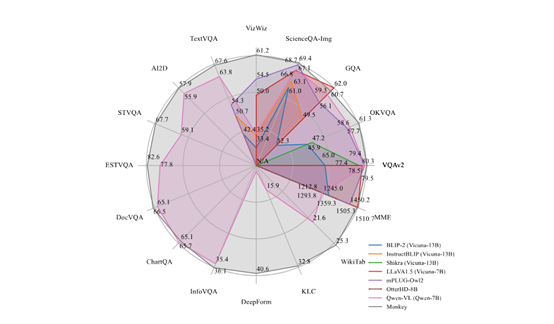
为了验证Monkey的能力,研究人员在16个不同的数据集上进行全面验证,覆盖图像字幕、通用VQA、文档VQA等测试任务。
通用视觉问答:Monkey在VQAv2、GQA、OKVQA等多个数据集上都显示出明显的优势。
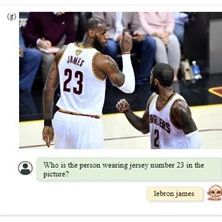
图像字幕任务:Monkey在TextCaps数据集上的性能同样优异,证明了对图片中文本元素的多模态理解力。
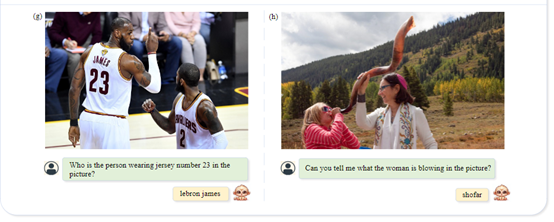
文档导向问答:Monkey在DocVQA、ChartQA、DeepForm等文档图像理解数据集上也取得了不错的成绩。
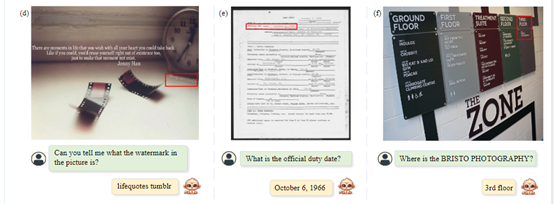
研究人员表示,Monkey在细微视觉信息感知和复杂场景理解上展现出了超强能力,在医学影像、卫星图像等领域拥有广泛的应用空间。未来,也会继续优化Monkey模型,提升其感知、联想、推理和泛化能力。
本文素材来源Monkey论文,如有侵权请联系删除
END

本篇文章来源于微信公众号: AIGC开放社区



