极大提升GPT-4等模型推理效率,微软、清华开源全新框架
添加书签

专注AIGC领域的专业社区,关注微软OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
随着用户需求的增多,GPT-4、Claude等模型在文本生成、理解、总结等方面的能力越来越优秀。但推理的效率并不高,因为,多数主流模型采用的是“顺序生成词”方法,会导致GPU利用率很低并带来高延迟。
为了解决这一难题,清华和微软研究院开发了一种SoT(Skeleton-of-Thought,思维骨架)框架并开源了项目。SoT首先引导大语言模型生成答案的骨架,然后使用并行API调用或批量解码来完成内容每个骨架点的填充,可极大提升模型的推理效率。
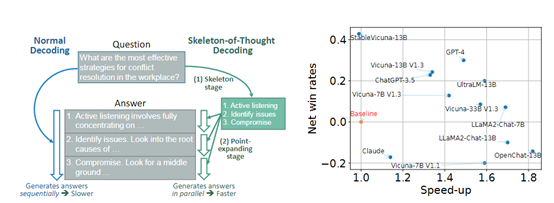
为了验证SoT的效果,研究人员在Vicuna-80和WizardLM两个对话数据集上测试了12个模型,包括GPT-4、LLaMA、Claude等。
数据显示,在SoT的帮助下,大多数模型的推理延迟减少了1.5—2.4倍。例如,在Vicuna-80数据集上,使LLaMA的33B参数量模型的推理延迟从43秒降低到16秒。除了效率的提升,研究人员发现,SoT可以提高模型的回答质量。
开源地址:https://github.com/imagination-research/sot/
论文地址:https://arxiv.org/abs/2307.15337

SoT的最大创新点在于,采用了一种拟人化的思考方式。通常,人类在回答某个问题时,会先根据某些原则和策略拟定思路框架,然后再扩充每个要点的细节。
例如,我们在制定公司发展战略时,会先制定一个大的框架然后分模块具体去执行。
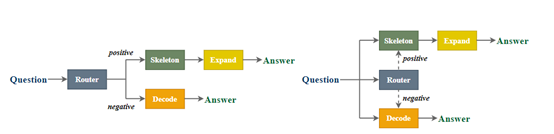
这种方法比一步一步的顺序生成方法高效的多。所以,SoT的技术架构也并不复杂主要由骨架生成和内容填充两大部分组成。
骨架生成
该模块就是直接生成内容的整体架构。骨架生成模块使用了特制的提示模板,指导语言模型直接输出骨架。
提示模板明确要求语言模型用1.,2.,3.等序号的形式输出3-10个要点,每个要点内容保持在3-5个词的长度。

同时提供了完整的任务描述,确保语言模型理解所要完成的工作,以及部分回答“1.”来让语言模型遵循正确的格式继续书写。
由于语言模型生成的骨架回复大多符合预期的编号要点格式,因此,可以用正则表达式提取出要点及其内容。
内容补充
当模型拿到骨架后,SoT会为每个编号要点并行地生成详细内容。内容补充也使用特制的提示模板。
提示模板明确要求语言模型只关注扩展指定的要点,并用1-2句很短的话完成扩展。同时提供了原问题、已生成的完整骨架和要扩展的要点序号及内容,确保语言模型理解上下文。
为了实现推理效率加速,SoT采用了批量解码或并行API请求,使语言模型并行地扩展多个要点,大大缩短获取最终回答所需的时间。
研究人员表示,SoT这种从内容结构优化的方法,将比其他系统底层、架构的方法简单、高效的多。尤其是随着内容产出的高速增长,发挥的作用也会越发明显。
但SoT也存在一些不足的地方,例如,当逻辑推理需要前后步骤之间的相互依赖时,SoT会自动切换至顺序生成模式。
本文素材来源SoT论文,如有侵权请联系删除
END

本篇文章来源于微信公众号: AIGC开放社区



