专注AIGC领域的专业社区,关注微软OpenAI、百度文心一言、讯飞星火等大语言模型(LLM)的发展和应用落地,聚焦LLM的市场研究和AIGC开发者生态,欢迎关注!
随着扩散模型的飞速发展,诞生了Midjourney、DALL·E 3、Stable Difusion等一大批出色的文生图模型。但在文生视频领域却进步缓慢,因为文生视频多数采用逐帧生成的方式,这类自回归方法运算效率低下、成本高。
即便使用先生成关键帧,再生成中间帧新方法。如何插值帧数,保证生成视频的连贯性也有很多技术难点。
科技、社交巨头Meta则提出了一种全新的文生视频模型Emu Video。该模型使用了分解式生成方法,先生成一张图像,再以该图像和文本作为条件生成视频,不仅生成的视频逼真符合文本描述,算力成本也非常低。
论文:https://emu-video.metademolab.com/assets/emu_video.pdf
在线demo:https://emu-video.metademolab.com/#/demo
Emu Video的核心技术创新在于,使用了分解式生成方法。之前,其他文生视频模型是直接从文本描述映射到高维视频空间。
但由于视频维度非常高,直接映射非常困难。Emu Video的策略是首先生成一张图像,然后以该图像和文本作为条件,生成随后的视频帧。
由于图像空间维度较低,生成第一帧更容易,然后生成后续帧只需要预测图像如何变化,这样整个任务难度很大程度降低。
技术流程方面, Emu Video利用先前训练好的文本到图像模型来固定空间参数,初始化视频模型。
然后仅需要训练时间参数来进行文本到视频任务。在训练时,模型以视频片段及相应文本描述作为样本进行学习。
在推理时,给定一段文本后,先用文本到图像部分生成第一帧图像,再输入该图像及文本到视频部分生成完整的视频。
Emu Video使用了一个训练好的文本到图像模型,可以生成很逼真的图片。为了让生成的图片更有创意,这个模型在海量的图像和文本描述进行预训练,学到了很多图像的风格,例如,朋克、素描、油画、彩绘等。
文本到图像模型采用了U-Net结构,包含编码器和解码器。编码器包含多层卷积块,并降采样获得较低分辨率的特征图。
解码器包含对称的上采样和卷积层,最终输出图像。两个文本编码器(T5和CLIP模型)被并行加入,分别对文本进行编码产生文本特征。
这个模块使用了跟文本到图像模块类似的结构,也是一个编码器-解码器结构。不同的是增加了处理时间信息的模块,也就是说可以学习如何把图片中的内容变化成一个视频。
在训练的过程中,研究人员输入一小段视频,随机抽取其中的一帧图片,让这个模块学习根据这张图片和对应的文本生成整段视频。
在实际使用时,先用第一个模块生成第一帧图片,然后输入这张图片和文本给第二个模块,让它生成整个视频。
这种分解的方法让第二个模块的任务变得比较简单,只需要预测图片会随着时间而怎么变化和运动,就可以生成流畅逼真的视频。
为了生成更高质量逼真的视频,研究人员进行了一些技术优化:1)采用零终端信噪比的散度噪声计划,能够直接生成高清视频,无需级联多个模型。之前的计划在训练和测试阶段信噪比存在偏差,导致生成质量下降。
2)利用预训练文本到图像模型固定参数,保留图像质量和多样性,生成第一帧时不需额外训练数据和计算成本。
3)设计多阶段训练策略,先在低分辨率训练快速采样视频信息,再在高分辨率进行微调,避免全程高分辨率的计算量大。
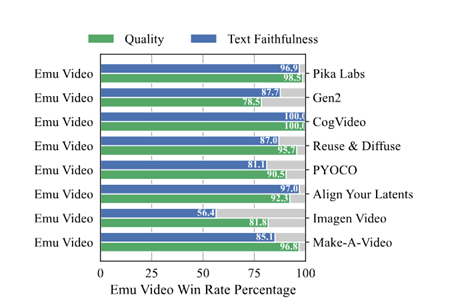
在人类评估中显示,Emu Video生成的4秒长视频比其他方法更具质量和遵循文本的要求。语义一致性超过86%,质量一致性超过91%,明显优于Gen-2、Pika Labs、Make-A Video等知名商业模型。
本文素材来源Meta官网,如有侵权请联系删除
END
 《遇见未来 发现AI视觉艺术》故事接龙AI短片大赛
《遇见未来 发现AI视觉艺术》故事接龙AI短片大赛