用MEG重构人类大脑成像过程,Meta发布重磅研究!
添加书签

专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
全球社交、科技巨头Meta(Facebook、Instagram等母公司)在官网公布了一项重磅研究,通过MEG(脑磁图)开发了一种AI模型用于解码人类大脑中视觉活动的成像过程,并公布了论文。
据悉,这是一种每秒可进行数千次大脑活动侦测的,非侵入式神经成像技术,可实时重构出大脑在每一刻感知和处理的图像。可为科学界理解大脑如何表达、形成图像,提供了重要研究基础。
从应用场景来看,该技术能更好地理解、控制ChatGPT、Stable Difusion等AI模型的神经网络行动、神经元,提升内容输出准确率降低风险,向AGI(通用人工智能)演变奠定了基石。
放眼更大的目标,将加速“脑机接口”在临床方面的研发进程,帮助那些遭受脑损伤失去说话能力的人。
论文地址:https://ai.meta.com/static-resource/image-decoding
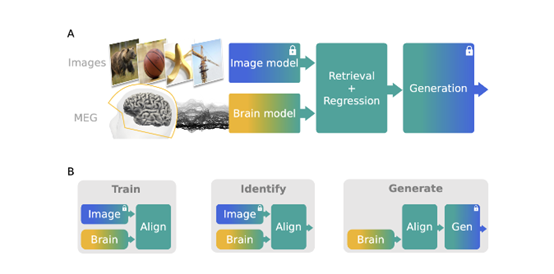
技术原理
从Meta发布的论文来看,Meta通过MEG开发的AI模型原理并不复杂,主要包含图像编辑、大脑、图像解码三大模块。
当我们的大脑进行活动时,会产生微弱的电流。根据物理定律,这些电流会引起周围磁场的变化。利用MEG高度敏感的仪器检测这些磁场变化,从而获得脑部活动的数据。
具体来说,MEG使用特殊的超导扼流计作为探测器。这些扼流计由超导环路组成,可以精确地捕捉到磁场的微小波动。
探测器的位置经过精心设计,覆盖头部周围,测试者只需要坐在MEG仪器中保持头部静止即可。
MEG重构实验者大脑成像,每个图像大约每1.5秒呈现一次。
虽然大脑电流活动引起的磁场强度非常微小,但MEG的探测器经过放大和处理就可以清晰地记录下来。
MEG包含200-300个探测器,每个探测器的位置都对应大脑的特定区域。这样,MEG可以获得高时间分辨率的全头脑活动数据。
一旦获得原始的MEG数据,研究人员就可以利用强大的神经网络对其进行解码,提取重要的视觉信息,用于重构大脑图像。
Meta表示,最初想使用功能磁共振成像(fMRI)来搜集人类大脑的电流信息,但在图像分辨率、图像间隔以及连续性方面都不如MEG。
图像编辑模块
该模块基于多个预训练的计算机视觉模型,从输入图像中提取语义特征向量,作为解码的目标表示。研究人员比较了监督学习模型、图像-文本匹配模型、自监督模型等,发现CLIP和DINO的表现最佳。
CLIP(Contrastive Language-Image Pretraining)通过图像-文本匹配进行预训练,获得泛化能力强的视觉语义特征。DINO(Distributional Invariance for Normalization)是一种自监督对比学习方法。
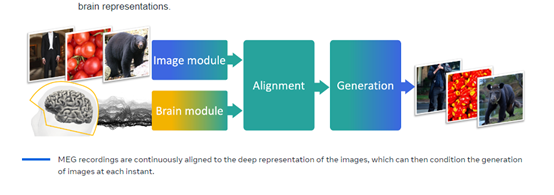
以CLIP为例,可以提取图像模块(CLIP-Vision)的平均特征或分类标记(CLS)特征,文本模块(CLIP-Text)的平均特征,并拼接组合作为图像的语义特征表示。
大脑模块
该模块使用卷积神经网络,用于输入MEG数据窗口,输出是预测的图像特征向量。需要端到端训练,学习将MEG的数据映射到图像输出的latent space。
研究人员使用了卷积神经网络结构,包含残差块和膨胀卷积块,可以捕捉MEG时序信息。同时添加注意力层、主体专属层等机制。
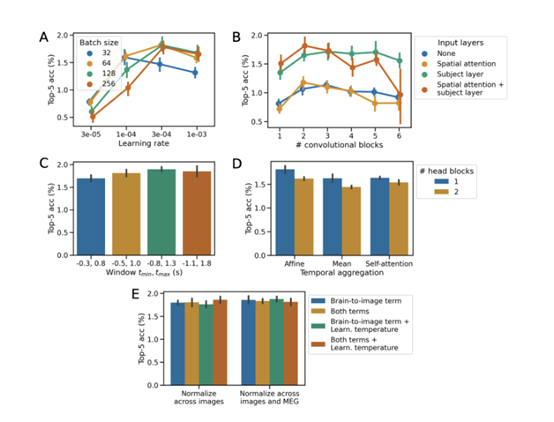
为了进行图像检索,大脑模块以CLIP损失函数为目标,学习最大化匹配图像的特征相似度。为进行图像生成,大脑模块以MSE损失为目标,直接预测图像模块的特征。
图像解码模块
为了更好地解码图像,研究人员使用了latent diffusion扩散模型,将大脑模块预测的特征向量作为条件,可以生成与输入图像语义一致的新图像。
将大脑模块输出的CLIP语义特征和AutoKL特征作为条件,指导模型生成语义一致的图像。利用DDIM采样算法,以及噪声引导等技巧,逐步从噪声分布生成清晰的图像。一般采用50步采样过程。

最后,使用感知指标(SSIM)和语义指标(CLIP相似度、SwAV特征相关度),评估图像的解码、生成质量。
实验测试方面,研究人员使用包含4名参与者的MEG数据集THINGS-MEG,该数据集包含22,448张唯一的自然图像。
通过MEG的测试,研究人员发现大脑对图像的反应,主要集中在刺激出现后0-250ms的时间段,生成的图像能够保留语义信息。虽然生成的图像不是很完美,但结果表明重构的图像保留了丰富的高级特征。
本文素材来源Meta官网、论文,如有侵权请联系删除
END





