智谱AI&清华KEG开源AgentTuning,全新对齐Agent微调方法
添加书签
专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
为探索提升智能体任务之间的促进及泛化效果,智谱AI&清华KEG提出了一种对齐Agent能力的微调方法 AgentTuning,该方法使用少量数据微调已有模型,显著激发了模型的 Agent能力,同时可以保持模型原有的通用能力。
10月21日,智谱AI官方宣布开源经过 Agent 对齐的语言模型(AgentLM:能打的 Agent 模型来了!7B,13B,70B 全开源),包括 AgentLM-7B,AgentLM-13B,AgentLM-70B,及 相应的数据集 AgentInstruct,目前模型和数据集均可在魔搭社区体验(文末见体验链接&推理实践代码)。
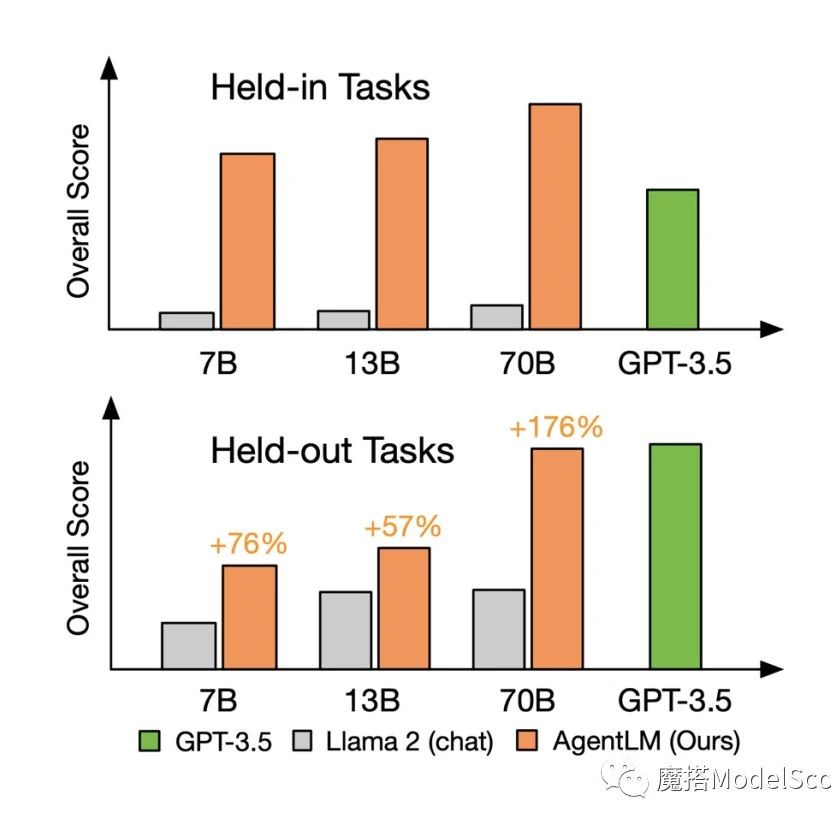
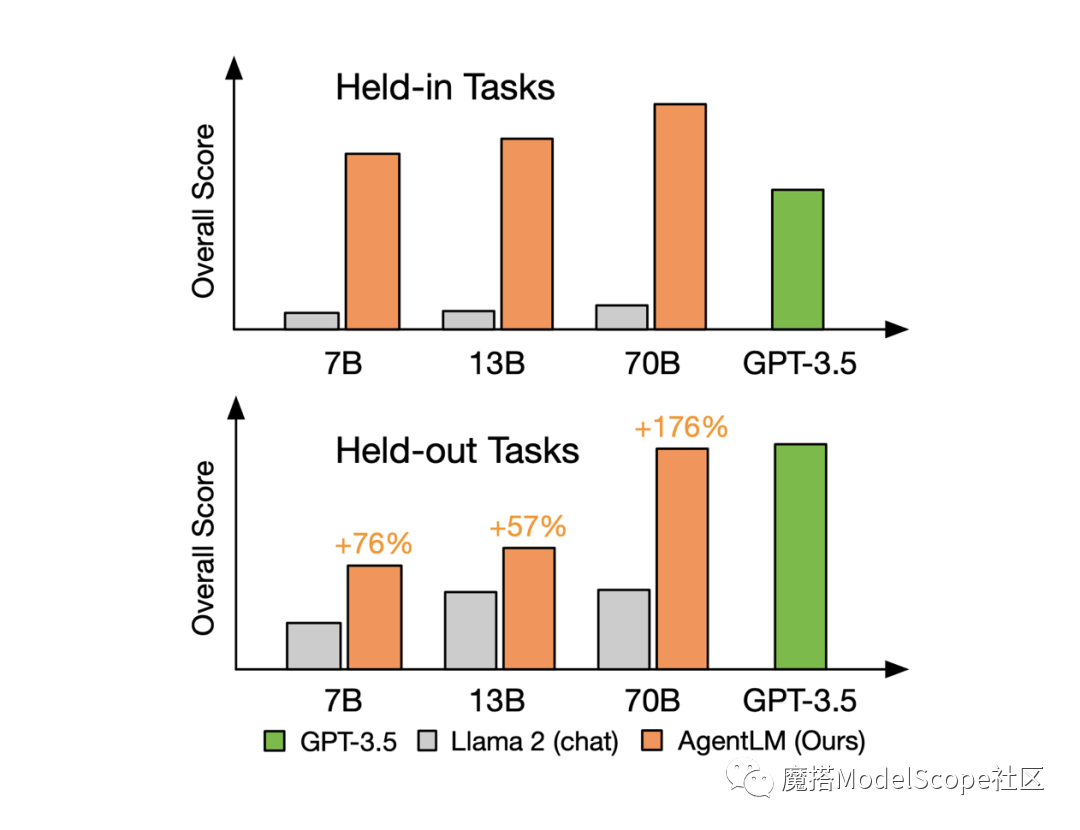
据官方实验介绍,使用 AgentTuning 方法对 Llama-2-chat 系列模型进行微调,在微调过程中,将 20% 的 AgentInstruct 数据集和 80% 的通用数据进行混合训练,得到了 AgentLM-7B,AgentLM-13B,AgentLM-70B。
经过微调的模型,内分布任务(Held-in Tasks)中 AgentLM-7B 的综合分数便可达到 GPT-3.5-turbo 的水平;外分布任务(Held-out Tasks,训练过程中未见过的任务)中 AgentLM-70B 模型可以取得与 GPT-3.5-turbo 相当的水平。
更多详细信息,可以参考其论文和 Github 内容
模型&数据集:
-
模型
-
agentlm-7b
-
agentlm-13b
-
agentlm-70b
https://modelscope.cn/models/ZhipuAI/agentlm-70b/summary
-
数据集:
https://modelscope.cn/models/ZhipuAI/agentlm-7b/summary
https://modelscope.cn/models/ZhipuAI/agentlm-13b/summary
附:魔搭推理代码
(推理代码支持在PAI-DSW的免费算力环境下运行)
import torchfrom modelscope import Model, AutoTokenizermodel = Model.from_pretrained("ZhipuAI/agentlm-7b", revision='master', device_map='auto', torch_dtype=torch.float16)tokenizer = AutoTokenizer.from_pretrained("ZhipuAI/agentlm-7b", revision='master')prompt = """<s>[INST] <<SYS>>You are a helpful, respectful and honest assistant.<</SYS>>There's a llama in my garden 😱 What should I do? [/INST]"""inputs = tokenizer(prompt, return_tensors="pt")# Generategenerate_ids = model.generate(inputs.input_ids.to(model.device), max_new_tokens=512)print(tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0])
运行结果:

本文来源魔搭ModelScope社区,如有侵权请联系删除
END





