RLAIF:通过AI反馈,提升人类反馈强化学习
添加书签
专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
人类反馈的强化学习(RLHF)是大语言模型成功的关键技术之一。通过使用强化学习(RL)进行训练,可以优化复杂、序列级的目标,而这些目标不容易用传统的监督式微调进行微分。
但扩大RLHF规模的一个难点是,对高质量人类标签的需求。有多项研究表明,大型语言模型与人类判断的一致性很高,甚至在某些任务上的效率超过人类。因此,谷歌研究人员提出了一种基于AI反馈的强化学习——RLAIF。
RLAIF可产生与RLHF类似的结果,例如,在摘要任务上,人类评估员在约70%的情况下,更喜欢RLAIF和RLHF的生成结果,而不是监督微调。此外,当被要求评价RLAIF与RLHF摘要时,人类对两者的喜好程度相等。
论文地址:https://arxiv.org/abs/2309.00267

什么是RLHF
RLHF的英文为Reinforcement Learning with Human Feedback,中文译为“人类反馈强化学习”,是一种结合人类指导和自动强化学习的训练方法。人类通过对AI的行为进行评价或指导,帮助其在学习过程中做出更好的决策,优化输出内容。
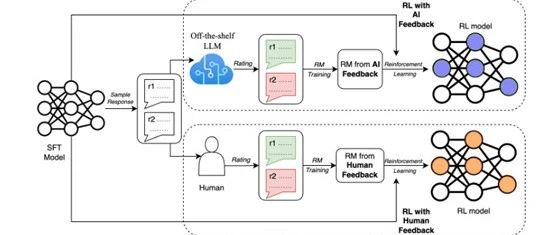
RLHF主要包含监督微调、奖励建模和强化学习三个主要流程:1)监督微调,使用人类提供的反馈,对预训练的语言模型进行微调,以适应特定的下游任务;2)奖励建模,根据人类标注的偏好,训练一个奖励模型;3)强化学习,使用奖励模型,通过强化学习对模型进行进一步的微调。
RLHF在ChatGPT等大语言模型的预训练过程中,在微调、优化输出、拟人化等方面发挥了巨大作用。很多开源大语言模型生成的文本内容非常生硬甚至有点“傻”,这是因为缺少RLHF的支持或核心训练数据不足。
但RLHF需要高质量、精准数据标签,并且需要专业人员按照特定数据标注手册执行。因此,对于一些中小企业来说使用RLHF需要耗费大量人力资源和财力,同时存在个人偏见使数据集不准确。
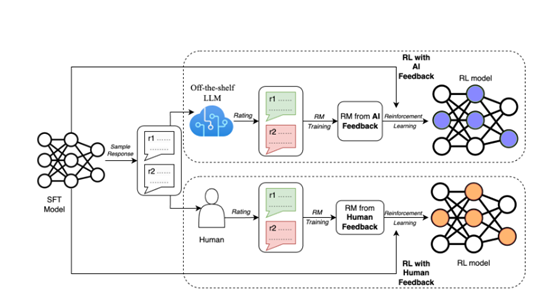
RLAIF方法
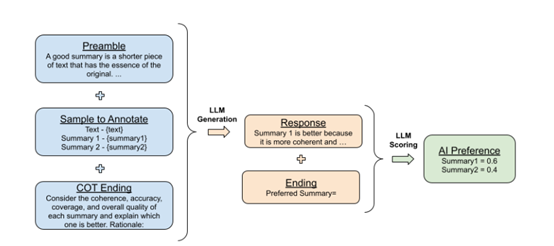
研究人员使用大语言模型对测试数据进行了标签注释。在标记好后,训练了一个奖励模型来预测偏好。由于实验的方法产生了软标签(例如,preferencesi = [0.6, 0.4]),将交叉熵损失应用于奖励模型生成的奖励分数的softmax,而不是第2.2节中提到的损失。softmax将奖励模型的无界分数转换为概率分布。
在AI标签的数据集上训练奖励模型,可以被视为一种模型蒸馏的形式,尤其是因为AI标注器通常比奖励模型更强大。
另一种方法是绕过奖励模型,直接将AI反馈作为强化学习中的奖励信号,但这种方法在计算上更昂贵。
有了训练过的奖励模型,研究人员使用改编到语言建模领域的优势算法的修改版本,进行最后的强化学习。
RLAIF与RLHF对比
该研究标明,以两种方式衡量RLAIF的性能与RLHF几乎相当。首先,人类对RLAIF和RLHF的策略的偏好,分别为71%和73%,超过了监督微调(SFT)的基线,这两个结果并无统计学上的显著差异。
其次,当被要求直接比较RLAIF与RLHF的生成结果时,人类对两者的偏好程度相等(即50%)。这些结果表明,RLAIF是对RLHF的一种可行的替代方案,它不依赖于人类的注释。

此外,还研究了如何最大化AI生成的偏好,与人类偏好的对齐程度的技术。结果显示,用详细的指令提示大语言模型,并征求连贯的思考推理可以提高数据对齐度效率。
本文素材来源谷歌论文,如有侵权请联系删除
END




