开源视觉模型DINOv2允许商用,Meta最新视觉评估模型炸场!
添加书签
专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
9月1日,全球社交、科技巨头Meta(Facebook、Instagram等母公司)在官网宣布,允许开源视觉模型DINOv2商业化,同时推出视觉评估模型FACET。
DINOv2是Meta在今年4月开源的视觉模型,采用了全新的高性能计算机视觉模型训练方法,无需微调具备自我监督学习的强大功能。
主要用于图像分类、实例检索、视频理解、深度估计、语义分割等。该模型的应用范围非常广泛,例如,世界资源研究所通过DINOv2绘制虚拟森林地图。
此前,DINOv2一直只能用于技术研究,现在,Meta宣布其可在 Apache 2.0 许可证下进行商业化。Meta还发布了一系列基于 DINOv2 的密集预测模型,用于语义图像分割和深度评估,为开发、研究人员提供更大的灵活性来探索其在业务中的应用。
开源地址:https://github.com/facebookresearch/dinov2
演示地址:https://dinov2.metademolab.com/
论文:https://arxiv.org/abs/2304.07193

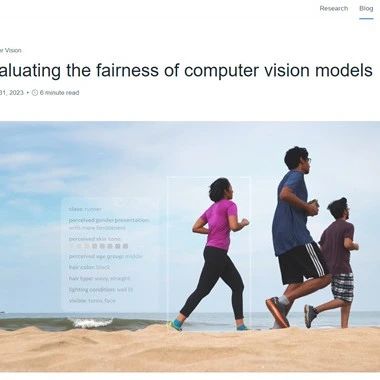
FACET是Meta最新发布的视觉评估模型,主要用于检测、评估视觉模型的标签、分类、实例分割等,例如,评估图片人物的性别、肤色、光线等,有助于提升模型的准确性。

据悉,FACET是基于一个由50,000张人物图片和32000张物体图片数据集开发而成,同时包含来自SA-1B的69,000个口罩的人物、头发和衣服标签。
目前,Meta已经开放了FACET数据集下载,帮助开发人员用于技术研究和功能迭代。
FACET数据集下载地址:https://ai.meta.com/datasets/facet-downloads/
FACET论文:https://ai.meta.com/research/publications/facet-fairness-in-computer-vision-evaluation-benchmark/
FACET的评估数据集中的每一张图片,皆由Meta聘请的专业人工数据标注专家构建而成。可评估图片中人物的年龄、肤色、头发、配饰、纹身、帽子等物品。
标注专家还为图像中的人物定义了职业和相关活动,例如医生、消防员或吉他手等。

通过对FACET的使用可极大增强模型的分类、语义切割等任务的准确性,减少歧视、非法、暴力等内容的输出。
为了验证效果,Meta展示了使用FACET评估了DINOv2、OpenCLIP、SEERv2三个视觉模型的识别效果。
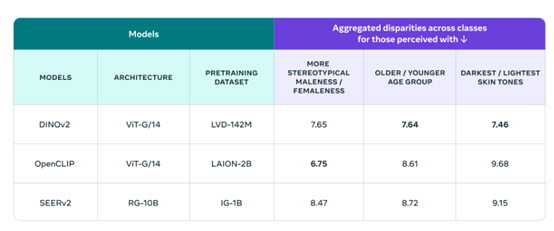
结果显示,在评估男性/女性刻板印象方面、年龄、肤色三个属性,对DINOv2、OpenCLIP、SEERv2的识别能力做出了准确的评估。
本文素材来源Meta官网,如有侵权请联系删除
END




