可商业化!阿里云通义千问开源两款,超强中英文70亿参数模型
添加书签

专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
近日,AI模型社区魔搭ModelScope上架两款开源模型Qwen-7B和Qwen-7B-Chat,阿里云确认其为通义千问70亿参数通用模型和对话模型,两款模型均开源、免费、可商业化。(开源地址:https://modelscope.cn/models/qwen/Qwen-7B-Chat/summary)
据悉,通义千问-7B(Qwen-7B)是阿里云研发的通义千问大模型系列的70亿参数规模的模型。Qwen-7B是基于Transformer的大语言模型, 在超大规模的预训练数据上进行训练。预训练数据类型多样,包括大量网络文本、专业书籍、代码等。
同时,阿里云在Qwen-7B的基础上,使用对齐机制打造了类ChatGPT的AI助手Qwen-7B-Chat。在多个权威测评中,通义千问7B模型取得了远超国内外同等尺寸模型的性能,成为业界最强的中英文7B开源模型。
github地址:https://github.com/QwenLM/Qwen-7B
huggingface地址:https://huggingface.co/Qwen/Qwen-7B-Chat

Qwen-7 B系列技术亮点
1)使用高质量的预训练数据进行训练:已经在一个自构建的超过2.2万亿个令牌的大规模高质量数据集上预训练了Qwen-7B。该数据集包括纯文本和代码,并且它覆盖了广泛的领域,包括通用领域数据和专业领域数据。
2)性能强劲:与同尺寸的相似模型相比,Qwen-7 B在一系列基准数据集上的表现优于竞争对手,这些数据集评估了自然语言理解、数学、推理、编码等。
3)更好的语言支持:Qwen-7 B的tokenizer基于超150 K令牌的大词汇表,与其他tokenizer相比更有效。对多种语言很友好,有助于用户进一步对Qwen-7 B进行微调,以扩展对某种语言的理解。
4)支持8 K上下文长度:Qwen-7 B和Qwen-7 B-Chat都支持8 K的上下文长度,这允许用户输入更长的内容。
5)支持插件:Qwen-7 B-Chat使用与插件相关的对齐数据进行训练,因此它能够使用工具,包括API,模型,数据库等,并且它能够作为代理来使用。
性能评测
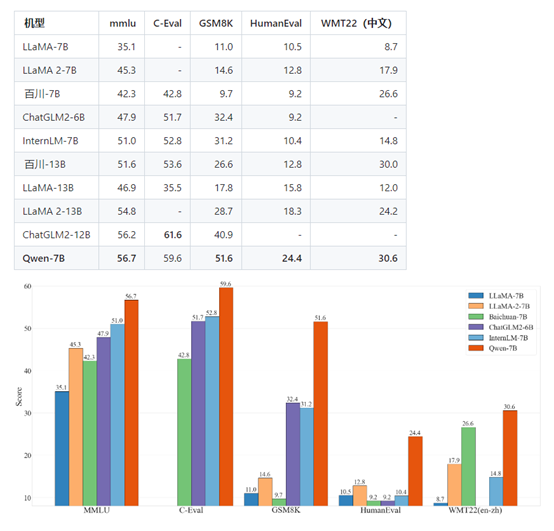
通义千问7B预训练模型在多个权威基准测评中表现出色,中英文能力远超国内外同等规模开源模型,部分能力甚至“跃级”赶超12B、13B尺寸开源模型。
在英文能力测评基准MMLU上,通义千问7B模型得分超过一众7B、12B、13B主流开源模型。该基准包含57个学科的英文题目,考验人文、社科、理工等领域的综合知识和问题解决能力。
在中文常识能力测评基准C-Eval上,通义千问在验证集和测试集中都是得分最高的7B开源模型,展现了扎实的中文能力。
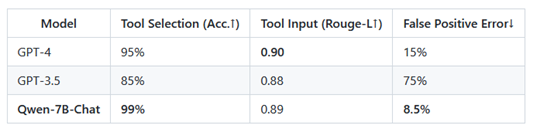
此外,Qwen-7 B-Chat专门针对API、数据库、模型等工具进行优化,方便用户可以构建基于Qwen-7 B的LangChain(浪链)、Agent(代理)和代码解释器等。
阿里云表示,开源大模型可以帮助用户简化模型训练和部署的过程,用户不必从头训练模型,只需下载预训练好的模型并进行微调,就可快速构建高质量的模型。
相比英文世界热闹的AI开源生态,中文社区缺少优秀的基座模型。通义千问的加入有望为开源社区提供更多选择,推动国内AI开源生态建设。
本文素材来源阿里云通义千问,如有侵权请联系删除
END




