重磅!Meta发布类ChatGPT开源模型Llama 2,允许商业化!
添加书签

专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
美东时间7月18日,Meta(Facebook、Instagram等母公司)在官网发布了类ChatGPT开源大语言模型——Llama 2(开源地址:https://github.com/facebookresearch/llama)
据悉,Llama 2是在Llama基础之上构建而成,拥有70亿、130亿和700亿三种参数。还有一种340亿参数正在训练中并没有在此次发布。
与一代Llama相比,Llama 2最大亮点之一是允许商业化,任何企业、个人开发者都能将其用在商业用途,例如,开发生成式AI助手、聊天机器人、增强个人应用等。
有一点需要注意,根据Meta的商业协定显示,如果使用Llama 2的企业月活人数超过7亿,将需要向Meta申请特定的商业许可。
论文:https://ai.meta.com/research/publications/llama-2-open-foundation-and-fine-tuned-chat-models/
Llama 2详细介绍
此外,美东时间7月18日微软召开了“Microsoft Inspire 2023”大会,并宣布与Meta达成技术合作,将在Windows和Azure云服务中提供LLama 2。两大科技巨头的强强联手,将再一次改变生成式AI的发展格局。
用户可以在Azure上,安全可靠地使用或微调70亿、130亿和700亿三种参数的LLama 2模型。同时Llama 2可以在 Windows上本地运行,这使得Windows 开发人员将能够通过 ONNX以 DirectML执行提供程序为目标来使用该模型,从而在为应用程序集成生成式 AI 体验时实现无缝工作流程。
微软表示,将Llama 2 大语言模型集成在Windows 中,有助于推动 Windows 成为开发人员构建针对客户需求量身定制的生成式AI体验的最佳开发平台。
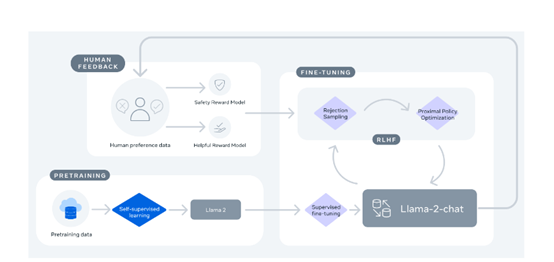
技术方面,Llama 2 预训练模型接受了2万亿个标记的训练,上下文长度是Llama 1的两倍。其微调模型已经接受了超过100 万个人类注释的训练。
Llama 2 在许多外部基准测试上的表现,都优于其他开源语言模型,包括推理、编码、熟练程度和知识测试等。

训练数据方面,Llama 2 的数据集包含了来自公开可用资源的混合数据。Llama 2 采用了 Llama 1 中的大部分预训练设置和模型架构,包括标准 Transformer 架构等。
本周一「AIGC开放社区」发布了Meta即将发布一款可商业化的类ChatGPT大语言模型的消息,没想到来的如此迅速这对于整个类ChatGPT开源界将产生巨大影响。
Llama被誉为类ChatGPT开源模型的“鼻祖”,几乎国内外所有知名开源项目等都是基于或借鉴了该产品。但LLaMA一直有一个致命缺点,无法商业化,只能用于学术研究。
现在,Meta正式发布了Llama 2解决了这一痛点并允许商业化,使得更多的企业、个人开发者可以快速加入到生成式AI热潮中。

本文素材来源Meta官网,如有侵权请联系删除
END




