终于来了!类ChatGPT开源“鼻祖”,即将允许商业化
添加书签

专注AIGC领域的专业社区,关注OpenAI、百度文心一言等大语言模型(LLM)的发展和应用落地,关注LLM的基准评测和市场研究,欢迎关注!
金融时报消息,Meta(Facebook、Instagram、WhatsApp等母公司)将很快发布一款可商业化的类ChatGPT大语言模型,并为企业提供定制化、微调等服务。
据知情人士透露,Meta此举是为了追赶微软、谷歌、OpenAI的脚步,扩大开源生态影响力以抢夺市场份额、提升产品影响力。
早在今年2月份,Meta开源了4种参数的大语言模型LLaMA,算是类ChatGPT开源模型的“鼻祖”,几乎国内外所有知名开源项目,例如,Alpaca、Guanaco、LuoTuo、Vicuna、Koala等都是基于或借鉴了该产品。但LLaMA一直有一个致命缺点,无法商业化,只能用于学术研究。

Meta副总裁兼首席AI科学家Yann LeCun,在上周六普罗旺斯艾克斯举行的一次会议上表示,AI竞争格局将在未来几个月,甚至未来几周内彻底改变。届时将会出现与非开源平台,一样好的开源项目。
这很可能是对新的可商业化开源大语言模型的暗示。
早前,All in元宇宙的Meta吃尽了苦头,不仅亏了100多亿美元股价连续遭遇重创,元宇宙的建设却遥遥无期望不到头。
由ChatGPT掀起的生成式AI风暴让Meta看到了新的发展方向。今年2月,Meta率先开源了70亿、130亿、330亿和650亿参数的大语言模型LLaMA。(开源地址:https://github.com/facebookresearch/llama/)
LLaMA模型与ChatGPT同样是基于Transformers模型演变而来。在数据训练方面,LLaMA使用公开可用的数据集进行训练,其中包括开放数据平台Common Crawl、英文文档数据集C4、代码平台GitHub、维基百科、论文预印本平台ArXiv等,总体标记数据总量大约在1.4万亿个Tokens左右。
Meta认为,在更多标记(单词)上训练的较小模型,更容易针对特定的潜在产品用例进行再训练和微调。例如,LLaMA在1.4万亿个Tokens上训练了330亿和650亿参数;在1万亿个Tokens上训练了70亿参数。
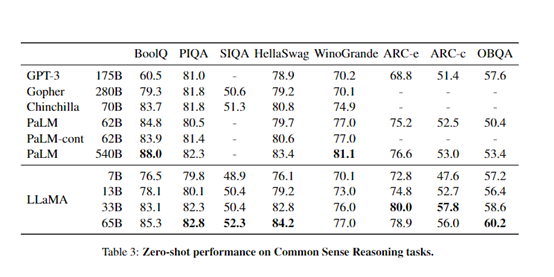
内容方面,LLaMA可生成文本、代码等。为了扩大文本边界,LLaMA使用了20多种语言文本进行训练。LLaMA整体性能在开源界处于领先地位。
除了大量投资生成式AI技术,在场景化落地方面Meta同样非常积极。广告一直是Meta的核心收入来源之一。但在2021年 苹果推出App Tracking Transparency功能后对Meta的广告收入造成了严重影响,仅2022年便损失了100亿美元。
根据埃森哲的预测,到2029年,30%的社交媒体广告是由生成式AI自动生成,但是关键审核流程仍然由人工完成。
因此,为了提升广告客户体验,加快广告制作效率和降低开发成本,Meta在今年5月发布了AI Sandbox,帮助企业自动生成广告。
目前,有数百万企业在Meta旗下的社交平台投放广告,Meta希望企业通过AI Sandbox
产品可以加速广告制作流程并节省成本。AI Sandbox主要提供多文本生成、背景生成、图片裁剪三大功能。
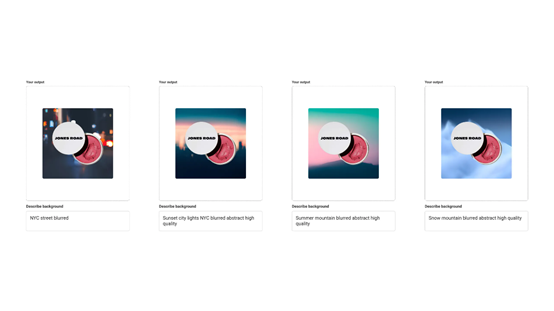
多文本生成:可以自动成多个文本内容,突出广告商文案的重点,可以针对特定受众尝试不同内容。
背景生成:根据文本输入创建背景图像,让广告商可以更快速地尝试各种背景并丰富创意素材。
图像裁剪:调整创意素材以适应多个平台的不同纵横比,如 Stories 或 Reels,让广告商在重构创意素材上节省时间和资源。
Meta追赶生成式AI热潮,预计未来会发布更多的AI产品并将其应用在实际业务中。
本文素材来源金融时报,如有侵权请联系删除
END




