基于扩散模型的,开源世界模型DIAMOND
添加书签
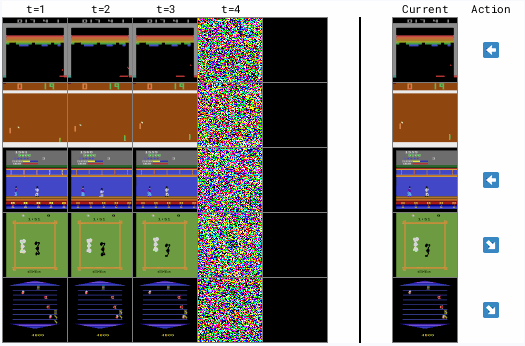
日内瓦大学、微软研究院和爱丁堡大学的研究人员联合开源了,基于扩散模型的世界模型—DIAMOND。
研究人员之所以选择扩散模型作为基础,是因为可以更好地捕捉视觉细节,同时具有建模复杂多模态分布的能力,以便在不同的环境下进行训练和细致的行为观察。
DIAMOND主要用于智能体训练、世界建模、多模态分布建模等多种强化学习应用。为了评估其性能,研究人员在Atari 100k上进行了综合测试。
结果显示,DIAMOND不仅在视觉复杂度高的环境中能够生成连贯且高质量的轨迹,还取得了平均为1.46的测试分数,在训练智能体方面非常强。
论文地址:https://arxiv.org/abs/2405.12399
Github地址:https://github.com/eloialonso/diamond


最近几年,强化学习在游戏、机器人控制和自动驾驶等领域得到了应用,但其样本、训练效率低的问题仍是扩大应用范围的关键难点。
为了克服这一困难 “世界模型”作为一种辅助工具应运而生,使智能体能够在模拟环境中学习规划、决策等拟人化思维。
但现有世界模型多依赖于序列化的离散潜变量,来模拟环境动态,这可能导致视觉细节的损失,而这些细节对于强化学习至关重要。所以,DIAMOND使用了一种基于扩散模型的创新架构,可以捕捉更丰富的视觉信息。
扩散模型
扩散模型是DIAMOND的核心模块,主要通过逆向学习噪声过程来生成高质量的视觉数据。这种模型与传统的基于离散潜在变量的方法有显著不同,因为它能够生成更加丰富和细致的视觉信息。
扩散模型不仅能生成数据,还构成了世界模型的基础,负责模拟环境的动态变化。这意味着,给定过去的观察和动作,DIAMOND能够预测未来的观察、奖励和终止状态。

DIAMOND通过扩散模型可以生成连续的潜在变量序列,这些序列捕捉了环境状态的细微变化。对于强化学习智能体来说至关重要,因为它们需要准确地理解环境的动态,才能制定有效的策略。
奖励模型
在强化学习中,智能体的行为是由环境提供的奖励信号来引导的,可预测智能体在执行特定动作后所获得的奖励。奖励模型使得智能体能够评估其行为,并据此调整其决策能力。

在DIAMOND中,奖励模型可以采用多种不同的形式,如神经网络或其他机器学习模型。这些模型通过学习大量的交互数据,能够捕捉到观察和动作与奖励之间的复杂映射关系。
终止模型
终止模型的作用是可以帮助智能体,识别何时一个任务已经完成或需要重新开始。例如,在自动驾驶的场景中,智能体需要知道何时到达了目的地。
终止模型的工作原理基于对智能体历史行为和观察的分析。它通过学习智能体与环境交互的数据来预测,何时结束当前执行的各种事件。

终止模型通常采用机器学习算法来实现,如决策树、逻辑回归或神经网络等。这些算法能够从历史数据中学习事件结束的模式,并据此进行预测。
例如,在一个游戏场景中,智能体需要再失去所有生命时来预测结束。而终止模型便能够识别导致游戏结束的行为和状态,并预测未来可能出现的类似情况。
本文素材来源DIAMOND论文,如有侵权请联系删除



