Arena-Hard:开源高质量大模型评估基准
添加书签
开发一个安全、准确的大模型评估基准通常需要包含三个重要内容:1)稳定识别模型的能力;2)反映真实世界使用情况中的人类偏好;3)经常更新以避免过拟合或测试集泄漏。
但传统的基准测试通常是静态的或闭源的,同时大模型的技术发展和功能迭代比较,这凸显了建立具有高可分离性评估基准的必要性。
大模型研究组织Lmsys Org则开源了Arena-Hard。这是一个全新高质量大模型评估基准。
开源地址:https://github.com/lm-sys/arena-hard

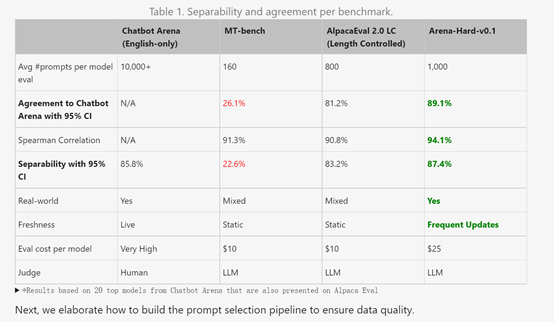
Lmsys将新的基准测试平台 Arena Hard v0.1 与当前领先的聊天 大模型基准测试 MT Bench 进行比较。
结果显示,Arena Hard v0.1 相对于 MT Bench 提供了明显更强的可分离性,且置信区间更窄。它还与 Chatbot Arena(仅限英文)的人类偏好排名具有更高的一致性(89.1%)。

Arena-hard-v0.1与广泛采用的大模型基准相比显示出最高的可分离性 (87.4%),并且也便宜且运行速度快(25 美元)。

Arena-hard-v0.1构建了一个管道,可以从通过 Chatbot Arena 收集的 200,000 个用户查询的数据集中自动提取高质量提示。这包括多样性,提示集应涵盖广泛的现实世界主题;提示质量,每个提示都应具有高质量来衡量大模型的水平。

为了确保提示多样性,Lmsys在BERTopic中采用主题建模管道,首先使用 OpenAI 的嵌入 (text-embedding-3-small) 转换每个提示,使用 UMAP 降维,并使用基于层次的聚类算法 (HDBSCAN) 来识别聚类然后使用 GPT-4-turbo 进行总结。这有助于Lmsys识别涵盖广泛领域的 4000 多个主题。
但主题集群在大模型基准测试中具有不同的质量和可分离性。Lmsys为大模型开发了一个经过校准的系统提示,帮助其根据七个关键标准例如,特异性、领域知识、问题解决能力等选择高质量的用户查询。

大模型Judge(GPT-3.5-Turbo、GPT-4-Turbo)对每个提示进行注释,从 0 到 7,以指示满足多少个标准。然后,Lmsys根据提示的平均得分对每个簇进行评分。
下面,Lmsys展示了从低到高平均分数的主题集群示例。例如,游戏开发或数学证明。另一方面,得分较低的集群指向琐碎或模糊的问题,例如“设计风格和影响”。

为了了解提示分数是否与可分离性相关,Lmsys对每个分数采样 50 个提示,并比较 GPT-4 和 Llama-70b 的响应,并以 GPT-4-Turbo 作为判断。
Lmsys表示高潜在得分与 GPT-4 对 Llama-70b 的胜率之间存在很强的相关性。在其他模型对中也观察到类似的趋势,例如Claude Sonnet 与 Haiku 以及Mistral-large 与 Mixtral。

本文素材来源Lmsys Org官网,如有侵权请联系删除



